近日,来自斯坦福、UC 伯克利、华盛顿大学等顶尖学术机构的科研团队联手发布了一款全新的SOTA(State-of-the-Art)级推理模型——OpenThinker-32B,并慷慨地开源了规模高达114k的训练数据集。这一重大成果不仅为AI推理领域注入了新的活力,也再次彰显了开源合作在推动科技进步中的巨大作用。
项目主页(https://www.open-thoughts.ai/blog/scale)和Hugging Face平台(https://huggingface.co/open-thoughts/OpenThinker-32B)上已经上线了OpenThinker-32B的相关信息,而数据集则可在Hugging Face的数据集页面(https://huggingface.co/datasets/open-thoughts/OpenThoughts-114k)上获取。
据了解,研究团队在探索中发现,采用经过DeepSeek-R1验证标注的大规模优质数据集,可以训练出性能卓越的推理模型。他们通过数据规模化、推理过程验证以及模型规模扩展等创新方法,成功打造出了OpenThinker-32B。在数学、代码和科学等多个基准测试中,OpenThinker-32B的性能表现令人瞩目,直接碾压了李飞飞团队的s1和s1.1模型,并且与DeepSeek-R1-Distill-32B的性能不相上下。
尤为值得一提的是,OpenThinker-32B在训练数据的使用上展现出了极高的效率。相比于DeepSeek-R1-Distill使用了高达800k的数据(其中包含600k个推理样本),OpenThinker-32B仅凭114k的数据就取得了几乎同等的优异成绩。这一数据使用效率的巨大提升,无疑为未来的AI推理模型训练提供了新的思路和方向。
除了亮眼的性能表现和数据使用效率外,OpenThinker-32B的开源程度也令人称赞。研究团队不仅公开了模型权重和数据集,还慷慨地分享了数据生成代码和训练代码。这种全方位的开源,不仅有助于其他研究人员在此基础上进行进一步的探索和创新,也为整个AI社区提供了宝贵的资源和启示。
在数据策展方面,研究团队使用了与之前训练OpenThinker-7B模型相同的OpenThoughts-114k数据集来训练OpenThinker-32B。他们利用DeepSeek-R1模型收集了精心挑选的17.3万个问题的推理过程和解答尝试,并将这些原始数据作为OpenThoughts-Unverified-173k数据集公开发布。在数据处理的最后一步中,如果推理过程未能通过验证,则过滤掉相应的数据样本。这一严谨的数据处理流程确保了训练数据的质量和可靠性。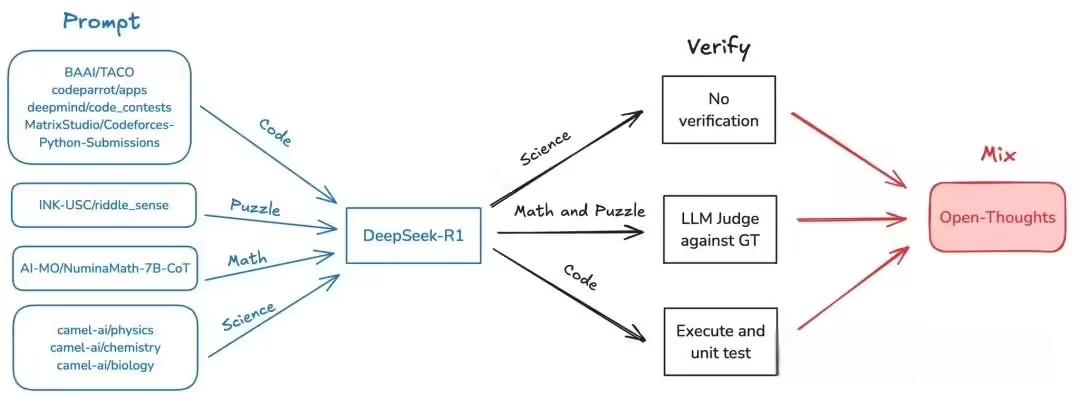
AI旋风认为,OpenThoughts-114k数据集中的额外元数据将使得该数据集更加易于使用。这些元数据包括用于数据集构建的额外列,如问题、标准答案、测试用例(仅限代码)、起始代码(仅限代码)、DeepSeek推理、DeepSeek解决方案、领域和来源等。这些元数据将使得研究人员能够更方便地进行数据过滤、领域切换、验证检查以及更改推理过程的模板等操作。
在验证方面,研究团队对答案进行了严格的验证,并剔除了不正确的回答。他们发现,保留那些未通过验证的推理过程可能会损害性能,但即使如此,未经验证的模型与其他32B推理模型相比仍然表现出色。这一发现为未来的数据验证和模型训练提供了新的视角和思路。
在训练方面,研究团队使用了LLaMa-Factory对Qwen2.5-32B-Instruct在OpenThoughts-114k数据集上进行了三轮微调,并在AWS SageMaker集群上使用四个8xH100 P5节点训练了90小时。同时,他们还训练了一个未经验证的版本——OpenThinker-32B-Unverified,在Leonardo超级计算机上使用了96个4xA100节点进行了30小时的训练。
在评估方面,研究团队使用了开源评估库Evalchemy对所有模型进行了评估。他们通过平均五次运行的结果来计算准确率,并采用了严格的评估配置来确保结果的准确性和可靠性。评估结果显示,OpenThinker-32B的性能已经几乎与DeepSeek-R1-Distill-Qwen-32B持平。
最后,研究团队对社区在过去几周在构建开放数据推理模型方面取得的快速进展表示振奋,并期待基于彼此的洞见继续向前发展。他们相信,OpenThinker-32B的开源将推动开源推理模型的发展,并为整个AI社区提供更多的启示和资源。
OpenThinker-32B的成功不仅在于其卓越的性能和数据使用效率,更在于其全方位的开源和合作精神。这一成果再次证明了数据、验证和模型规模的协同作用是提升推理能力的关键。我们期待未来能够看到更多像OpenThinker-32B这样的优秀模型涌现出来,为AI技术的发展注入更多的活力和创新。
相关文章
