据了解,NVIDIA携手德克萨斯大学奥斯汀分校的研究团队,共同推出了Flextron框架——这一创新成果不仅颠覆了传统AI模型部署的桎梏,更为资源有限环境下的AI应用开辟了全新路径。
在人工智能领域,大型语言模型(LLMs)如GPT-3和Llama-2以其卓越的语言理解和生成能力,成为了行业内的璀璨明星。然而,辉煌背后却隐藏着不容忽视的挑战——这些模型庞大的参数量如同一道高墙,阻挡了它们在更广泛场景下的应用。高昂的计算成本和资源需求,让许多潜在用户望而却步。
面对这一难题,传统方法往往采取“分而治之”的策略,即通过训练多个不同参数量的模型变体来适应不同的计算资源限制。然而,这种方法无异于“拆东墙补西墙”,不仅效率低下,还极大浪费了宝贵的数据和计算资源。正是在这样的背景下,NVIDIA和德克萨斯大学奥斯汀分校的研究人员联手推出了Flextron框架,为AI模型的灵活部署带来了革命性的变化。
Flextron框架的横空出世,标志着AI模型部署进入了一个全新的时代。作为一种新颖的灵活模型架构和后训练优化框架,Flextron的最大亮点在于其无需额外微调即可实现模型的适应性部署。这一特性彻底打破了传统方法的束缚,让AI模型能够像变形金刚一样,根据实际应用场景的需求自由变换,既保证了效率又兼顾了准确性。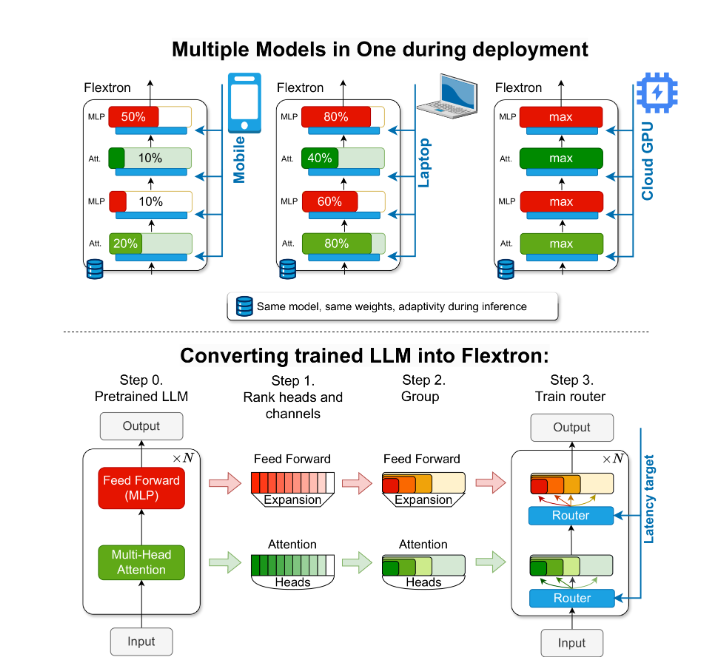
Flextron之所以能够实现如此惊人的灵活性,关键在于其独特的嵌套弹性设计。这种设计允许模型在推理过程中根据特定的延迟和准确性目标进行动态调整,从而确保在各种计算资源限制下都能达到最佳性能。此外,Flextron还采用了样本高效的训练方法和先进的路由算法,将预训练的LLM转化为弹性模型。这一过程不仅简化了模型部署的复杂度,还大大提高了资源利用效率。
Flextron框架的性能表现同样令人瞩目。在多个基准测试中,如ARC-easy、LAMBADA、PIQA、WinoGrande、MMLU和HellaSwag等,Flextron均展现出了卓越的性能。尤为值得一提的是,Flextron在仅使用原始预训练中7.63%的训练标记的情况下,就取得了令人惊叹的成绩,这无疑是对传统方法的一次有力反击。
更值得一提的是,Flextron框架还集成了弹性多层感知器(MLP)和弹性多头注意力(MHA)层等先进技术,进一步增强了其适应性。特别是弹性MHA层,能够根据输入数据的特性灵活选择注意力头的子集,从而在保证性能的同时有效降低了资源消耗。这一特性使得Flextron在计算资源有限的场景下更具竞争力。
随着Flextron框架的推出,AI模型的部署和应用将迎来更加广阔的空间。无论是云端服务器、边缘设备还是移动终端,Flextron都能凭借其灵活的适应性和高效的性能表现,为各行各业带来前所未有的变革。AI旋风相信,在不久的将来,Flextron将成为AI模型部署领域的标准配置,引领整个行业向更加智能化、高效化的方向发展。
总之,NVIDIA Flextron框架的推出是人工智能领域的一次重大突破。它不仅解决了传统模型部署过程中的诸多痛点问题,更为AI技术的广泛应用和普及提供了强有力的支持。我们有理由相信,在Flextron的助力下,人工智能将以前所未有的速度融入我们的生活和工作之中,开启一个全新的智能时代。
相关文章
