在人工智能的浩瀚星空中,算力与时间的双重桎梏长久以来如同两道难以逾越的天堑,限制了技术的飞跃与应用的广度。然而,今日,一种名为JEST(Joint Efficient Sampling for Training)的革新性数据筛选方法横空出世,它以惊人的效率重塑了AI训练的版图,预示着算力与时间瓶颈的突破性解决。
DeepMind团队的这一研究成果,不仅是人工智能领域的一次技术飞跃,更是对未来AI应用普及与深化的一次重大推动。JEST方法的诞生,从根本上挑战了传统大规模数据训练模式,通过智能筛选最佳数据批次进行训练,实现了训练周期的极速缩短与资源消耗的急剧降低。具体而言,该方法据称能将AI模型的训练时间缩短至原先的十五分之一,同时算力需求也大幅下降至原来的十分之一,这一成就无疑为AI技术的可持续发展铺设了坚实的基石。
JEST方法的核心策略在于其独特的联合选择机制,它不再局限于单个数据点的筛选,而是着眼于整个数据批次的优化组合。这一策略在多模态学习领域展现出了尤为显著的优势,通过减少不必要的迭代次数和浮点运算量,JEST在保持甚至提升训练效果的同时,实现了训练效率的飞跃。尤为值得一提的是,即便在仅使用十分之一计算资源(FLOP预算)的情况下,JEST依然能够超越当前最先进水平,这一成就无疑是对传统训练模式的一次颠覆性挑战。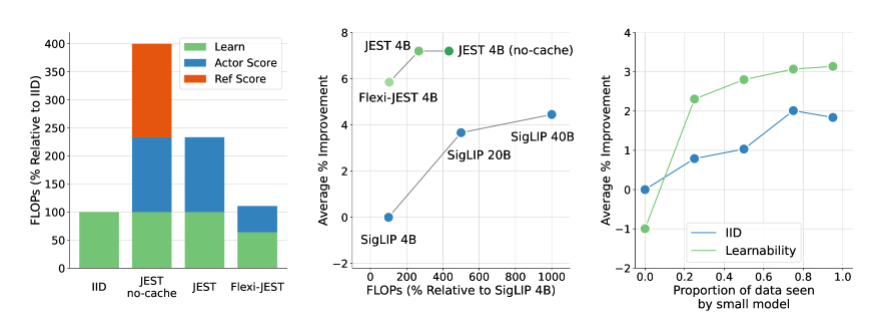
DeepMind团队的研究不仅停留在技术层面的创新,更在理论层面进行了深入的探索与验证。据了解,研究揭示了三大关键结论,为JEST方法的高效性提供了坚实的理论支撑:一是联合选择数据批次比单独挑选数据点更为有效;二是在线模型近似技术能够显著提升数据过滤的效率;三是通过引导小型高质量数据集,可以有效利用更广泛的非精选数据集资源。这些发现不仅解释了JEST方法为何能够如此高效,也为未来的AI训练策略提供了新的思考方向。
JEST方法的工作原理精妙而高效。它巧妙地借鉴了之前关于RHO损失的研究成果,通过结合学习模型与预训练参考模型的损失来评估数据点的可学习性。在此基础上,JEST选择那些对预训练模型来说较为容易识别,但对当前学习模型而言仍具挑战性的数据点进行训练,从而实现了训练效率的最大化。此外,JEST还引入了基于阻塞吉布斯采样的迭代方法,通过逐步构建数据批次并在每次迭代中根据条件可学习性评分精选新的样本子集,不断优化数据质量并提升训练效果。
随着JEST方法的问世与不断优化应用,AI旋风有理由相信,人工智能的发展将迎来一个全新的时代。算力与时间瓶颈的突破将极大地加速AI技术的研发与应用进程,推动AI在更多领域实现深度融合与创新。无论是医疗健康、智能制造还是智慧城市等领域,AI都将以更加高效、智能的姿态融入人们的生活与工作之中,开启一个充满无限可能的新纪元。
总之,DeepMind的JEST方法不仅是AI训练领域的一次重大突破,更是对未来AI技术发展路径的一次深刻洞察与引领。我们有理由期待,在不久的将来,随着更多类似创新成果的涌现与应用推广,人工智能将以前所未有的速度与深度改变我们的世界。
 渝公网安备50019002504809号
渝公网安备50019002504809号