在科技日新月异的今天,AI领域的每一次创新都引领着未来的风向标。近日,阿里通义实验室以“AI旋风”之势,正式开源了其精心研发的音频生成大模型项目——FunAudioLLM,这一里程碑式的举措不仅标志着大型语言模型(LLMs)与自然语音交互技术的深度融合,更为情绪语音对话、有声读物等多元化应用场景带来了前所未有的可能性。
FunAudioLLM的发布,是人工智能领域一次重要的技术飞跃,它通过两大核心模型SenseVoice与CosyVoice的强强联合,构建了一个既智能又富有情感的语音交互生态系统。这一系统不仅极大地丰富了人机交互的方式,还提升了交互的自然度与真实感,让机器的声音更加贴近人心。
CosyVoice,作为FunAudioLLM项目中的语音生成专家,以其卓越的多语言支持、音色与情感控制能力而著称。经过海量数据——多达15万小时的精细训练,CosyVoice不仅能够轻松驾驭中文、英文、日文、粤语、韩语五种语言,更能在零样本场景下迅速模拟出各种音色,实现跨语言声音合成的无缝切换。尤为值得一提的是,CosyVoice在情感和韵律的细粒度控制上展现出了惊人的能力,使得生成的语音不仅自然流畅,更能够准确传达出情感色彩,为用户带来沉浸式的听觉体验。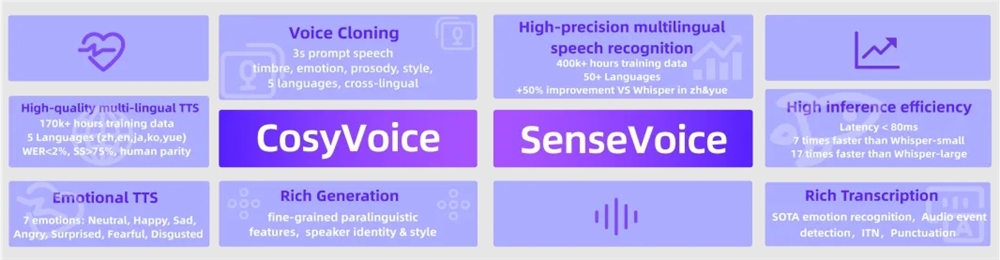
与CosyVoice相辅相成的SenseVoice,则是语音识别与情感辨识领域的佼佼者。依托40万小时的数据锤炼,SenseVoice支持超过50种语言的识别,其识别准确率不仅超越了业界知名的Whisper模型,更在中文和粤语等复杂语言环境下实现了显著提升,提升幅度超过50%。更令人惊叹的是,SenseVoice还具备情感识别和音频事件检测的能力,能够精准捕捉语音中的情感波动与周围环境的变化,为语音交互增添了更多人性化的维度。
FunAudioLLM的开源,意味着这些前沿技术将不再局限于实验室之中,而是能够广泛应用于多语言翻译、情绪语音对话、互动播客、有声读物等众多领域。通过无缝结合SenseVoice、LLMs与CosyVoice,FunAudioLLM能够实现从语音输入到语音输出的全链条处理,为用户带来前所未有的语音交互体验。无论是跨国界的无障碍沟通,还是个性化的情感交流,亦或是沉浸式的有声阅读体验,FunAudioLLM都能轻松驾驭,让机器的声音成为连接人与世界的桥梁。
FunAudioLLM之所以能够取得如此瞩目的成就,离不开其背后的技术原理与算法创新。CosyVoice基于先进的语音量化编码技术,确保了语音生成的自然流畅;而SenseVoice则凭借全面的语音处理功能,包括自动语音识别、语言识别、情感识别和音频事件检测,为语音交互提供了坚实的技术支撑。此外,阿里通义实验室在模型训练与优化方面也下足了功夫,确保了FunAudioLLM在性能与效率上的双重领先。
更令人振奋的是,阿里通义实验室将FunAudioLLM的模型与代码全部开源,并在ModelScope、Huggingface以及GitHub等平台上公开发布。这一举措不仅促进了AI技术的交流与共享,更为广大开发者提供了宝贵的资源与平台,鼓励大家共同探索语音交互的无限可能。AI旋风相信,随着FunAudioLLM的广泛应用与持续迭代,人类与机器之间的语音交互将会变得更加自然、智能与情感化,共同开启一个全新的AI时代。
相关文章
