在人工智能技术的浪潮中,阿里云再次展现了其创新实力,正式推出了Qwen2-Audio——一款颠覆传统、引领未来的音频多模态模型。这款模型以其卓越的音频处理能力和无需文字即可实现语音交互的特性,为语音交互领域树立了新的标杆。Qwen2-Audio的发布,标志着语音交互技术迈入了一个全新的发展阶段。
Qwen2-Audio不仅是一款单纯的音频处理工具,更是一个集音频分析与语音交互于一体的智能平台。它提供了两种独特的交互模式:音聊天和音频分析。用户无需繁琐的文字输入,仅凭语音即可与Qwen2-Audio进行流畅的交流,极大地提升了语音交互的便捷性和自然性。在音聊天模式下,用户可以与模型进行实时对话,享受更加人性化的沟通体验;而在音频分析模式下,Qwen2-Audio则能智能识别并解析音频中的信息,为用户提供精准的解释和反馈。
Qwen2-Audio的核心竞争力在于其强大的音频理解能力。该模型能够准确捕捉音频中的每一个细节,包括声音、多扬声器对话以及语音命令等,并据此做出恰当的响应。即使在复杂的音频环境中,Qwen2-Audio也能保持高度的敏感性和准确性,确保用户指令得到精准执行。此外,DPO(深度性能优化)技术的应用,使得Qwen2-Audio在事实性和期望行为遵守方面表现出色,进一步提升了用户体验。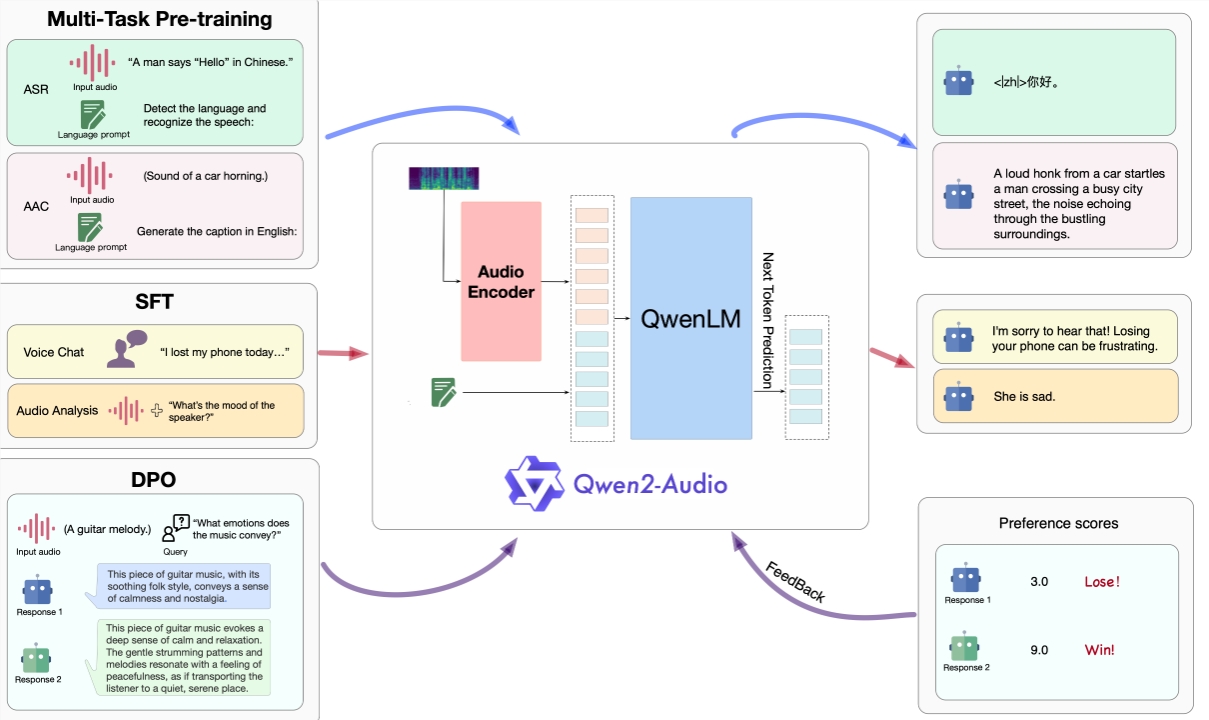
根据AIR-Bench的权威评估结果,Qwen2-Audio在音频为中心的指令跟踪功能测试中,展现出了超越以往SOTA(State-Of-The-Art)模型的卓越性能。特别是与Gemini-1.5-pro等领先模型相比,Qwen2-Audio在多个维度上均实现了显著的优势。这一成绩不仅证明了Qwen2-Audio的技术实力,也预示着它将在未来的语音交互市场中占据重要地位。
值得一提的是,Qwen2-Audio采用了开源策略,旨在促进多模态语言社区的共同发展。通过开放源代码和共享技术成果,阿里云希望能够吸引更多的开发者、研究者和爱好者参与到语音交互技术的研发中来,共同推动这一领域的持续进步和创新。
为了满足不同用户的需求,Qwen2-Audio系列将推出两款型号:Qwen2-Audio和Qwen-Audio-Chat。前者侧重于音频分析与处理功能,适用于需要高精度音频解析的场景;后者则专注于语音聊天体验,为用户提供更加便捷、自然的语音交互方式。两款型号的推出,将进一步丰富Qwen2-Audio的产品线,满足不同用户的多样化需求。
随着Qwen2-Audio的正式发布和不断优化升级,我们有理由相信,这款音频多模态模型将在未来的语音交互市场中发挥越来越重要的作用。它不仅将为用户带来更加便捷、高效的语音交互体验,还将推动整个语音交互技术的不断创新和发展。
相关文章
