在科技日新月异的今天,个性化推荐系统已成为连接用户与海量内容的重要桥梁。然而,面对短视频这一新兴且高度复杂的内容形态,传统推荐算法往往显得力不从心。近日,香港大学与腾讯的联合研究团队在AI领域投下了一颗震撼弹,他们提出了一种名为DiffMM(Diffusion-based Multi-Modal Recommendation Model)的全新多模态推荐系统范式,旨在通过创新的图扩散和对比学习技术,为短视频推荐带来前所未有的精准度与个性化体验。
在信息爆炸的时代,如何精准捕捉用户的兴趣偏好,成为推荐系统面临的核心挑战。港大与腾讯的研究团队深谙此道,他们推出的DiffMM系统,不仅是对传统推荐算法的颠覆,更是对多模态数据处理与利用的一次深刻探索。
DiffMM的核心魅力在于其独特的多模态图扩散模型。这一模型巧妙地构建了一个包含用户和视频信息的复杂图结构,该图不仅涵盖了用户的基本信息,还深入融合了视频的视觉、声音等多模态特征。通过这一多维度的信息整合,DiffMM能够更全面地理解用户与视频之间的潜在联系,为后续的精准推荐奠定坚实基础。
尤为值得一提的是,DiffMM采用了先进的图扩散技术来增强这一图结构。不同于传统的信息聚合方式,图扩散通过模拟信息的自然传播过程,使得用户与视频之间的关联得以在图中逐步扩散和强化。这一过程不仅增强了模型对用户偏好的捕捉能力,还有效降低了噪声数据的干扰,提升了推荐系统的鲁棒性。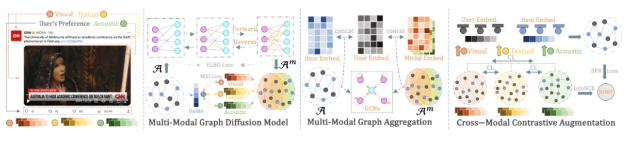
在技术实现层面,DiffMM的模型方法涵盖了多模态图扩散模型、多模态图聚合以及跨模态对比增强三大核心部分。其中,多模态图扩散模型通过模态感知去噪扩散概率模型,将用户-物品协同信号与多模态信息无缝对接,有效解决了多模态推荐系统中常见的负面影响问题。这一创新不仅提升了AI模型的准确性,还为用户带来了更加贴合个人喜好的推荐内容。
在多模态图聚合阶段,DiffMM利用图卷积操作对生成的模态感知用户-物品图进行深度聚合,实现了多模态信息的有效整合与利用。这一过程不仅增强了模型对复杂用户行为的理解能力,还进一步提升了推荐的个性化程度。
而跨模态对比增强技术则是DiffMM的另一大亮点。通过对比学习的方式,DiffMM能够捕捉不同物品模态上用户交互模式的一致性,从而确保推荐结果在不同维度上的高度一致性。这种跨模态的对比增强不仅提高了推荐系统的整体性能,还为用户带来了更加连贯和流畅的观看体验。
为了验证DiffMM的实际效果,研究团队在多个公共数据集上进行了大量实验。结果显示,DiffMM在各项指标上均显著优于现有的竞争性基线模型,达到了业界领先的SOTA水平。这一成果不仅证明了DiffMM技术的先进性和有效性,更为未来短视频推荐领域的发展指明了方向。
随着AI技术的不断进步和应用场景的持续拓展,多模态推荐系统正逐渐成为连接用户与内容的重要纽带。DiffMM的出现无疑为这一领域注入了新的活力与可能。它以其独特的图扩散和对比学习技术,为短视频推荐带来了前所未有的精准度和个性化体验。我们有理由相信,在不久的将来,DiffMM将成为推动短视频推荐乃至整个AI领域发展的重要力量。
相关文章
