在人工智能的浩瀚星空中,多模态大模型的研究正如火如荼地推进,国内外顶尖企业和研究机构纷纷亮出各自的“杀手锏”。从OpenAI的GPT系列到Google的Gemini,再到Microsoft的Phi-3V,每一款模型的发布都预示着技术的飞跃与突破。而今,国内科研力量也不甘落后,智源研究院携手大连理工大学、北京大学等顶尖学府,共同推出了新一代无编码器的视觉语言多模态大模型——EVE,为AI领域再次投下了一枚震撼弹。
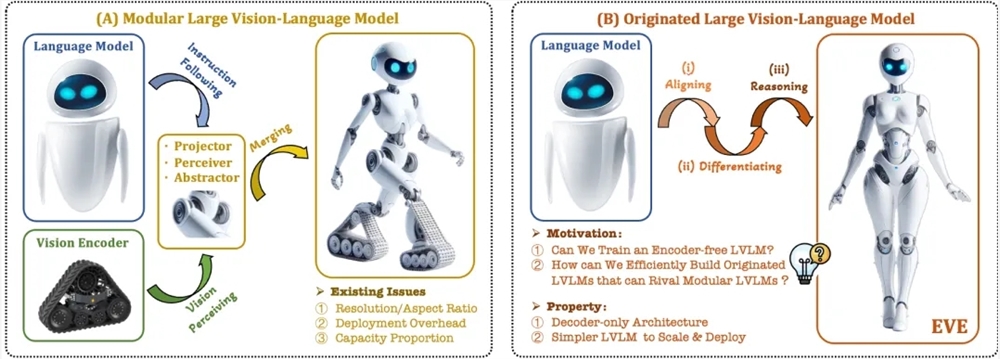
EVE的诞生不仅标志着国内在多模态大模型研究上的重大突破,更是对传统视觉语言模型架构的一次大胆革新。面对传统模型中普遍存在的训练分离导致的视觉归纳偏置问题,EVE以其独特的无编码器设计,从根本上解决了这一难题,为提升多模态大模型的部署效率和性能开辟了新的道路。
EVE的核心竞争力在于其创新的模型架构与训练策略。通过精细化训练策略和额外的视觉监督,EVE成功地将视觉-语言表征、对齐和推理整合到一个统一的纯解码器架构中。这一设计不仅简化了模型结构,还大大提高了模型的灵活性和处理效率。在多个视觉-语言基准测试中,EVE的表现令人瞩目,其性能接近甚至优于基于编码器的主流多模态方法,充分展示了其强大的潜力和广泛的应用前景。
EVE的主要特点可圈可点:
- 原生视觉语言模型:彻底去除视觉编码器,使得模型能够处理任意图像长宽比,避免了传统模型在图像尺寸限制上的弊端。与同类型Fuyu-8B模型相比,EVE在性能上实现了显著提升。
- 数据和训练代价少:EVE的预训练充分利用了OpenImages、SAM和LAION等公开数据资源,不仅降低了数据获取成本,还缩短了训练周期。这一特点使得EVE更加易于部署和推广。
- 透明和高效的探索:EVE为纯解码器的原生多模态架构提供了一条高效、透明的发展路径。这不仅有助于科研人员深入理解模型的工作原理,还为后续的优化和改进提供了有力支持。

模型结构层面,EVE同样亮点纷呈:
- Patch Embedding Layer:通过单层卷积层和平均池化层获取图像的2D特征图,有效增强了局部特征和全局信息的表达能力。
- Patch Aligning Layer:整合多层网络视觉特征,实现与视觉编码器输出的细粒度对齐,进一步提升了模型的视觉理解能力。
在训练策略上,EVE采用了分阶段的训练方法:
- 大语言模型引导的预训练阶段:通过大语言模型的引导,初步建立视觉和语言之间的联系,为后续训练奠定坚实基础。
- 生成式预训练阶段:提高模型对视觉-语言内容的理解能力,使其能够更准确地捕捉和表达图像中的信息。
- 监督式的微调阶段:通过监督式学习,规范模型遵循语言指令和学习对话模式的能力,进一步提升其实际应用效果。
EVE的推出不仅是对当前多模态大模型研究的一次重要补充和完善,更是对未来AI技术发展方向的一次深刻洞察和前瞻布局。随着技术的不断进步和应用场景的不断拓展,EVE有望在智能客服、自动驾驶、医学影像分析等多个领域发挥重要作用,推动AI技术与社会经济的深度融合与发展。
展望未来,智源研究院及其合作伙伴将继续深化对EVE的研究和优化工作,通过进一步的性能提升、无编码器架构的优化和原生多模态的构建等措施,不断推动多模态模型的发展与创新。我们有理由相信,在不久的将来,EVE将成为AI领域的一颗璀璨明星,引领多模态大模型研究的新潮流。
相关文章
