在人工智能的浩瀚星空中,大型语言模型(LLM)如同璀璨的星辰,照亮了自然语言处理(NLP)的征途。而今,复旦大学的研究团队以一场科技盛宴,再次点燃了业界的热情——他们推出了SpeechGPT2,一款能够深刻理解人类情感并生成多样语音风格的跨模态语言模型,其潜力直逼业界巨头GPT-4o。
SpeechGPT2的诞生,是人工智能领域一次里程碑式的飞跃。它不仅仅是一个简单的语音到文本的转换器或文本到语音的合成器,而是一个真正意义上能够“听懂”人类喜怒哀乐,并以相应情感与风格回应的智能伙伴。这种能力,让SpeechGPT2在人机交互的广度和深度上迈出了前所未有的步伐。
SpeechGPT2的核心魅力,在于其卓越的跨模态对话能力。它巧妙地将连续的语音信号进行离散化处理,使之能够与文本世界无缝对接,实现了语音与文本之间的自由穿梭。这一技术突破,为语言模型赋予了全新的生命力,让它们不再局限于单一的文本领域,而是能够跨越边界,探索更加丰富多彩的信息世界。
在训练过程中,复旦大学研究团队采取了前所未有的三阶段策略,为SpeechGPT2的卓越表现奠定了坚实基础。首先是模态适应预训练,通过海量未标记的语音数据,让模型逐渐适应并熟悉语音模态的奥秘;接着是跨模态指令微调,利用精心构建的SpeechInstruct数据集,模型学会了如何理解和执行跨模态的复杂指令;最后是模态链指令微调,进一步优化了模型在模态间转换的精准度和效率。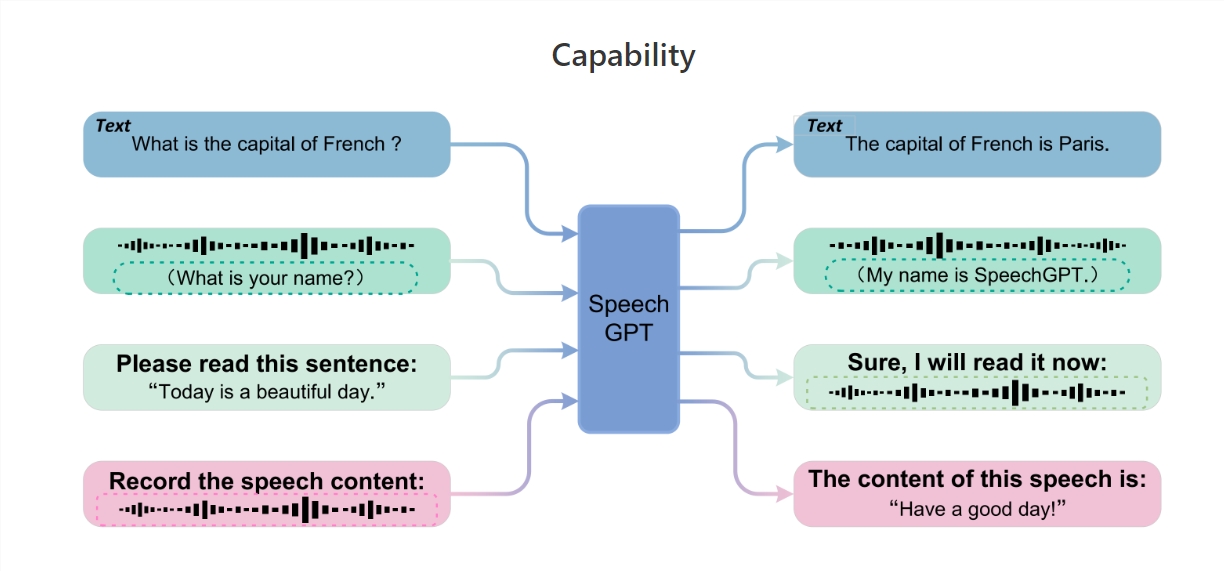
尤为值得一提的是,SpeechGPT2背后的SpeechInstruct数据集,它是首个大规模跨模态语音指令数据集,涵盖了丰富的任务类型和指令场景,为模型的训练提供了宝贵的资源。这一数据集的构建,不仅展现了复旦团队深厚的技术实力,也为整个AI社区贡献了一份宝贵的财富。
实验结果显示,SpeechGPT2在各类任务中均表现出色。无论是将语音精准转录为文本,还是将文本生动转换为语音,亦或是进行自然而流畅的口语对话,它都能游刃有余地应对。更令人惊叹的是,SpeechGPT2还能根据上下文和人类指令,灵活调整语音风格,从说唱到戏剧,从机器人到搞笑,甚至是细腻的低语,都能信手拈来,让每一次交流都充满惊喜和感动。
然而,需要注意的是,尽管SpeechGPT2已经取得了令人瞩目的成就,但在语音理解的噪声鲁棒性和语音生成的音质稳定性方面仍存在一定的提升空间。这主要是由于当前计算资源和数据资源的限制所致。不过,复旦团队已经明确表示,未来将开源技术报告、代码和模型权重,邀请全球的研究者共同参与到SpeechGPT2的进一步完善和发展中来。
随着SpeechGPT2的发布,我们仿佛看到了AI技术未来的无限可能。它不仅是复旦大学科研实力的集中展示,更是全球AI领域共同探索、共同进步的又一例证。我们有理由相信,在不久的将来,SpeechGPT2将以其卓越的性能和广泛的应用前景,成为推动人工智能产业发展的重要力量。
相关文章
