在人工智能的浩瀚星空中,视频理解一直被视为璀璨却难以触及的星辰。相较于静态图像,视频以其动态性、多维信息及复杂场景的交织,为AI理解能力设置了重重考验。然而,这一切随着谷歌研究团队最新推出的VideoPrism通用视频模型的横空出世,或将迎来历史性转折。
VideoPrism的诞生,是AI视频理解领域的一次革命性飞跃。 该模型以其卓越的跨任务表现,重新定义了视频理解的边界。VideoPrism不仅能够在视频分类、关键帧定位、字幕生成等基础任务上大放异彩,更能在复杂如视频问答等高级交互场景中展现出惊人的精准度与灵活性,真正实现了“一网打尽”的愿景。
VideoPrism的训练过程,犹如一场精心策划的知识盛宴。谷歌研究团队为其准备了超过3600万个高质量的视频-字幕对,以及海量的带有噪声的平行文本数据,这些数据覆盖了从日常生活琐碎到科学探索前沿的广泛领域。在如此庞大的数据集滋养下,VideoPrism学会了如何从纷繁复杂的视频世界中提炼出核心信息与深层含义。
VideoPrism的模型架构基于先进的视觉变换器(ViT),通过空间与时间的因子化设计,实现了对视频特征的精准捕捉。其训练算法更是别出心裁,结合了视频-文本对比学习与掩蔽视频建模两大策略。在第一阶段,VideoPrism通过对比学习,建立起视频与文本之间的深刻联系;而在第二阶段,掩蔽视频建模的引入,则进一步促进了模型对视频内容的深入理解与抽象概括。
在严苛的测试中,VideoPrism展现出了非凡的实力。在覆盖网络视频问答、科学计算机视觉任务等在内的33项基准测试中,VideoPrism在其中的30项上均达到了业界领先水平。这一成绩不仅是对其技术实力的有力证明,更是对未来AI视频理解应用前景的强烈预示。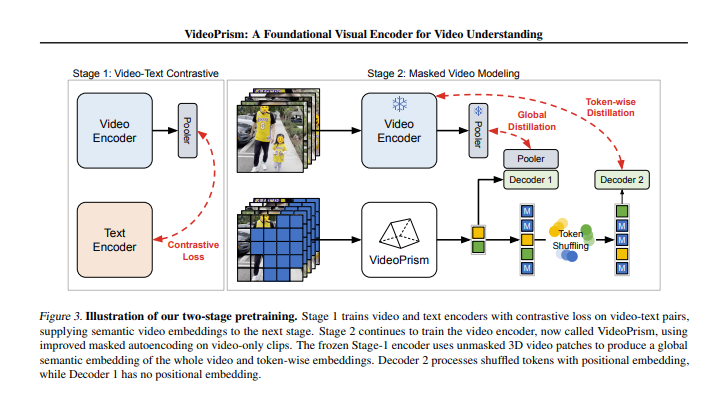
随着VideoPrism的问世,AI视频理解的应用边界将被极大拓展。在教育领域,它能帮助学生更加高效地获取视频课程中的关键信息;在娱乐产业,VideoPrism能助力内容创作者实现精准推荐与个性化定制;而在安全监控方面,其强大的视频分析能力更是为智能安防系统增添了新的利器。
然而,AI旋风也清醒地认识到,VideoPrism在前进的道路上仍面临诸多挑战。如何高效处理长视频数据,避免信息丢失与计算资源过度消耗;如何在训练过程中有效减少偏见,确保模型输出的公正性与准确性,都是亟待解决的问题。但正是这些挑战,为未来的研究指明了方向,也为VideoPrism乃至整个AI视频理解领域的发展注入了无限动力。
综上所述,AI旋风坚信,谷歌VideoPrism的推出不仅是技术层面的一次重大突破,更是AI视频理解领域迈向新纪元的标志性事件。随着AI技术的不断成熟与应用场景的持续拓展,我们有理由相信,一个更加智能、高效、便捷的视频理解时代即将到来。
相关文章
