在人工智能领域,谷歌DeepMind再次展现了其领先的技术实力。近日,DeepMind发布了一项名为V2A的视频转音频技术,这一革命性的技术能够通过视频像素和文本提示自动生成丰富的音轨,为无声视频赋予生命,实现同步视听生成。
V2A技术的核心在于其强大的音频生成能力。通过结合视频画面和用户提供的文字描述,V2A能够自动生成与视频内容紧密匹配的音轨,包括戏剧性配乐、逼真音效以及与视频人物和基调相匹配的对话镜头。用户还可以利用“正提示”或“负提示”来精确控制音频输出,确保生成的音轨完全符合创作需求。
在运作原理上,V2A系统首先将视频输入编码为压缩表示,然后利用扩散模型从随机噪声中提炼音频。这一过程在视觉输入和自然语言提示的引导下进行,确保生成的音频与视频内容高度同步且逼真。最后,音频输出被解码为音频波形,并与视频数据相结合,形成完整的视听作品。
为了确保生成的音频质量,DeepMind研究团队在训练过程中引入了更多信息。他们使用AI生成的注释,这些注释包含了声音详细描述和口头对话记录,帮助模型更好地理解特定音频事件与视觉场景的关联。通过这种方式,V2A技术能够学会将特定的音频事件与各种视觉场景联系起来,并根据注释或文本中的信息做出响应。
除了基本的音频生成功能外,V2A还具备多样化音轨生成的能力。用户可以通过系统生成无限数量的音轨,尝试不同的音效组合,找到最适合视频内容的声音。这种灵活性使得V2A成为创作者们不可或缺的工具,为他们的创作提供了更多的可能性。
然而,V2A技术并非完美无缺。在涉及到语音与唇形同步的问题时,V2A面临了一些挑战。虽然它能够根据输入的转录文本生成语音,但在与角色的唇形动作同步时可能会出现不匹配的情况。这是因为视频生成模型可能不以转录文本为条件,导致生成的嘴部动作与语音不匹配。为了解决这一问题,DeepMind团队正在不断改进技术,以提高唇形同步的准确性。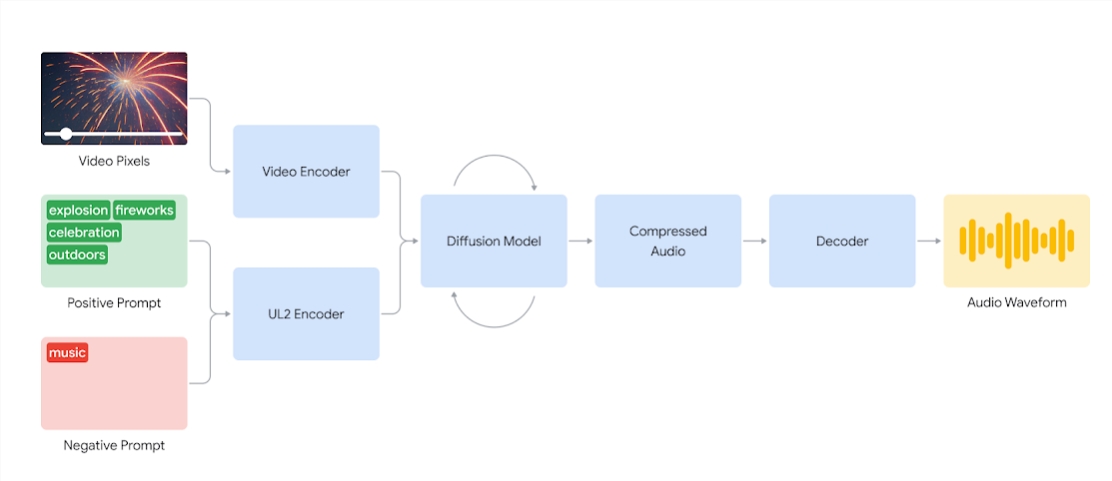
AI旋风认为,DeepMind的V2A技术为视频创作领域带来了革命性的变化。它不仅简化了音效制作的过程,还赋予了创作者更多的创作自由和灵活性。随着技术的不断发展和完善,我们有理由相信V2A将在未来为视频创作领域带来更多的惊喜和突破。
在发布之初,V2A技术将接受严格的安全评估和测试,以确保其稳定性和可靠性。一旦通过测试并面向公众开放,它将为电影、游戏、短视频等行业带来前所未有的便利和效率。同时,V2A技术也将为创作者们提供新的创作灵感和可能性,推动视频内容的创新和丰富。
以下是V2A技术生成的一些配音案例:
- 音频提示:狼对着月亮嚎叫,视频中呈现出一幅荒凉的夜晚景象,伴随着悠长的狼嚎声,营造出一种神秘而凄凉的氛围。
- 音频提示:电影、惊悚片、恐怖片、音乐、紧张感、氛围、混凝土上的脚步声,视频中展现出一座废弃的仓库,脚步声在空旷的走廊中回响,紧张的音乐和音效营造出一种恐怖的氛围。
- 音频提示:音乐会舞台上的鼓手被闪烁的灯光和欢呼的人群包围,视频中呈现出热闹的音乐会现场,鼓手的演奏声和观众的欢呼声交织在一起,营造出一种激动人心的氛围。
这些案例展示了V2A技术在不同场景下的应用能力,其生成的音效和配乐与视频内容紧密结合,为观众带来了更加沉浸式的观影体验。
相关文章
