在人工智能领域,谷歌DeepMind团队再次展现了其强大的创新能力。近日,他们公布了一项革命性的技术——利用AI模型为无声视频生成背景音乐的“video-to-audio”技术,为视频制作领域带来了全新的可能性。
据了解,这一技术并非一蹴而就,当前DeepMind的AI模型在配音方面还存在一定的局限性。具体来说,模型需要开发者使用提示词来预先“介绍”视频可能的声音,暂时还不能直接根据视频画面添加具体音效。然而,这并不影响其在无声视频配音领域的巨大潜力。
据DeepMind介绍,该模型首先会对用户输入的无声视频进行拆解,分析其画面内容和动态。随后,结合用户提供的文字提示,利用先进的扩散模型进行反复运算。这一过程中,模型会综合考虑视频画面与文字提示的信息,生成与视频内容相协调的背景声音。
例如,当输入一条描述“在黑暗中行走”的无声视频时,开发者可以添加“电影、恐怖片、音乐、紧张、混凝土上的脚步声”等文字提示。此时,DeepMind的AI模型便能根据这些提示,生成出具有恐怖风格的背景音效,如紧张的音乐、沉重的脚步声等,为视频营造出紧张刺激的氛围。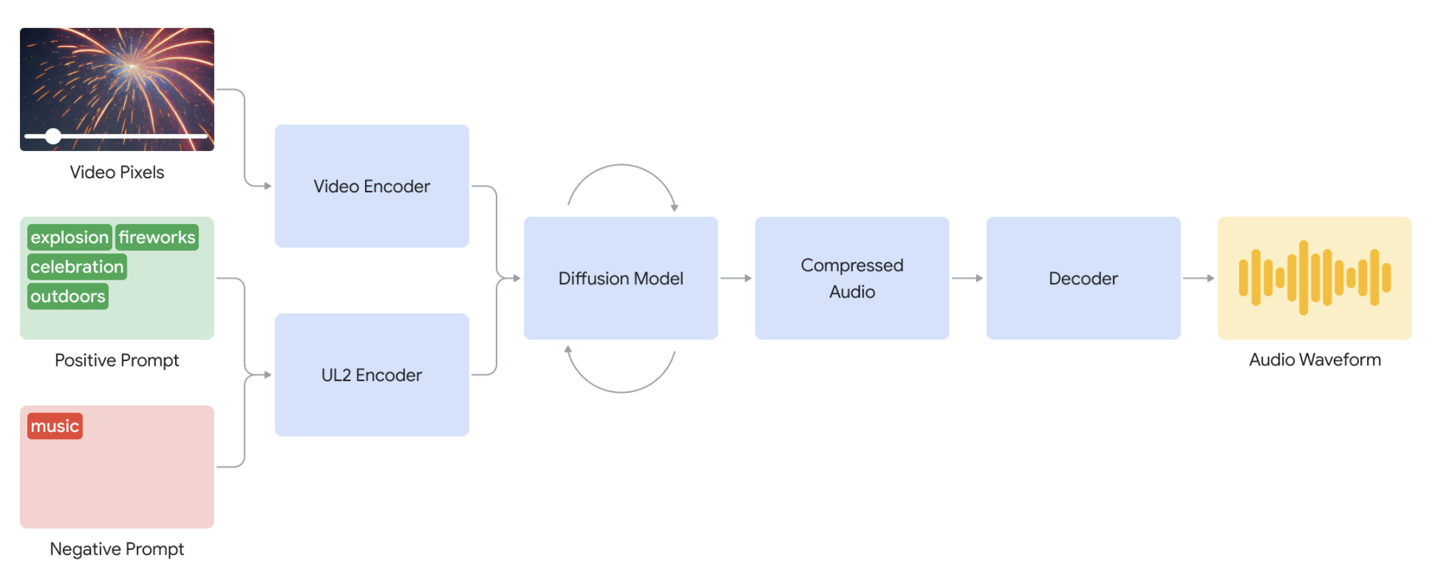
AI旋风认为,这一技术的出现,无疑为视频制作领域带来了极大的便利和可能性。传统的视频配音需要耗费大量的人力和时间,而DeepMind的“video-to-audio”技术则能够迅速地为无声视频添加合适的背景音乐和音效,大大提高了视频制作的效率。
更值得一提的是,DeepMind的AI模型具有极高的灵活性和可控性。它不仅可以为任何视频生成无限数量的音轨,还能够根据提示词内容判断生成的音频“正向性”或“反向性”,从而确保生成的声音更贴近特定场景。这为用户提供了极大的创意空间,使他们能够根据自己的需求来定制视频的音效。
展望未来,DeepMind表示他们正在进一步优化这款“video-to-audio”模型。未来的目标是让模型能够直接根据视频内容生成音频,而无需通过文字提示。这将使得配音过程更加智能化和自动化,进一步提高视频制作的效率和质量。
此外,DeepMind还计划改善视频中人物对白的口型同步能力。目前,许多视频在配音后常常会出现人物口型与声音不匹配的情况,这大大降低了观众的观影体验。DeepMind的新技术有望解决这一问题,使得配音后的视频更加逼真和生动。
AI旋风认为,谷歌DeepMind的这一新研究不仅展示了人工智能在音视频处理方面的巨大潜力,也为未来的视频制作领域带来了革命性的变化。随着技术的不断完善和发展,我们有理由相信这一技术将在未来发挥更加重要的作用,为视频制作领域带来更多的创新和突破。
相关文章
