在AI技术飞速发展的今天,视频生成领域迎来了新的突破。腾讯混元团队联合中山大学、香港科技大学共同推出了全新的图生视频模型——Follow-Your-Pose-v2,这一创新技术不仅实现了从单人到多人的跨越,更在视频生成质量、泛化能力等方面取得了显著进步,为电影内容制作、增强现实、游戏制作及广告等行业带来了无限可能。
Follow-Your-Pose-v2模型的推出,标志着图生视频技术在多人动作生成方面的重大突破。该模型能够在推理耗时更少的情况下,实现多人视频动作的生成,让合照中的每一个人都能同时在视频中动起来。这一技术的实现,不仅提升了视频生成的效率,更为用户带来了更为丰富的视觉体验。
Follow-Your-Pose-v2模型在泛化能力方面表现出色。无论年龄、服装、人种、背景杂乱程度或动作复杂性如何,该模型都能生成高质量的视频。这一特点使得该模型在日常生活照、抓拍视频等多种场景下都能得到广泛应用,为用户提供了更为便捷、高效的视频生成方式。
Follow-Your-Pose-v2模型在技术实现方面采用了多项创新技术。其中,光流指导器的引入使得模型能够充分利用背景光流信息,即使在相机抖动或背景不稳定的情况下,也能生成稳定的背景动画。此外,推理图指导器和深度图指导器的应用,使得模型能够更好地理解图片中的人物空间信息和多角色的空间位置关系,有效解决多角色动画和身体遮挡问题。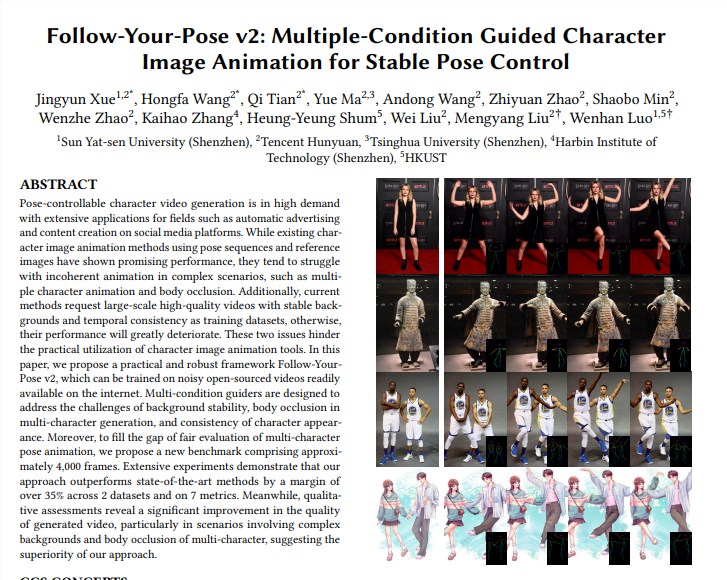
为了评估Follow-Your-Pose-v2模型的多角色生成效果,腾讯混元团队提出了一个新的基准Multi-Character,包含约4000帧多角色视频。实验结果显示,Follow-Your-Pose-v2在两个公共数据集(TikTok和TED演讲)和7个指标上的性能均优于最新技术35%以上。这一卓越的性能表现,充分证明了Follow-Your-Pose-v2模型在多人视频动作生成领域的领先地位。
图像到视频生成技术在电影内容制作、增强现实、游戏制作及广告等多个行业有着广泛的应用前景。Follow-Your-Pose-v2模型的推出,无疑为这些行业带来了更为高效、便捷的视频生成方式。AI旋风认为,随着AI技术的不断发展和完善,Follow-Your-Pose-v2模型将在未来发挥更加重要的作用,推动相关行业的快速发展。
值得一提的是,腾讯混元团队还公布了文生图开源大模型(混元DiT)的加速库,该加速库能够大幅提升推理效率,生图时间缩短75%。此外,混元DiT模型的使用门槛也得到了大幅降低,用户可以在Hugging Face的官方模型库中用三行代码调用模型。这一举措无疑将吸引更多开发者加入到图像到视频生成技术的研究和应用中来,共同推动该领域的繁荣发展。
总之,腾讯推出的全新图生视频模型Follow-Your-Pose-v2在多人视频动作生成方面取得了显著突破,为相关行业带来了无限可能。随着技术的不断发展和完善,我们有理由相信,这一技术将在未来发挥更加重要的作用,引领图像到视频生成技术的新纪元。
相关文章
