在人工智能的浪潮中,腾讯再次凭借其强大的研发实力,引领了一场技术革新。近日,腾讯公司正式开源了一款名为V-Express的创新模型,该模型能够利用人像照片生成动态视频,为肖像视频生成领域带来了新的发展机遇。
V-Express模型以其独特的逐步丢弃技术,实现了对姿态、输入图像和音频等多种控制信号的平衡与利用。这种技术方法通过一系列精心设计的操作,使得在以往容易被忽视的弱信号,如音频等,得以在视频生成中发挥重要作用。
腾讯的研发团队表示,V-Express模型在会说话的人脸生成任务中表现尤为出色。当目标视频与参考角色不是同一个人时,选择与参考人脸姿势更相似的目标视频,能够获得更为自然和真实的效果。这一特性使得V-Express在娱乐、广告、虚拟偶像等多个领域具有广泛的应用前景。
在肖像视频生成领域,使用单个图像生成视频的方法正逐渐成为研究的热点。然而,如何实现对多种控制信号的有效利用,尤其是当控制信号中存在强信号和弱信号时,一直是一个技术难题。
V-Express模型通过其独特的逐步丢弃操作,成功解决了这一问题。该模型能够在生成过程中逐步丢弃那些对结果影响较小的控制信号,从而使得剩余的控制信号,包括那些原本较弱的信号,得以在视频生成中发挥更大的作用。这种技术方法不仅提高了视频生成的质量,还为多条件生成提供了新的可能性和思路。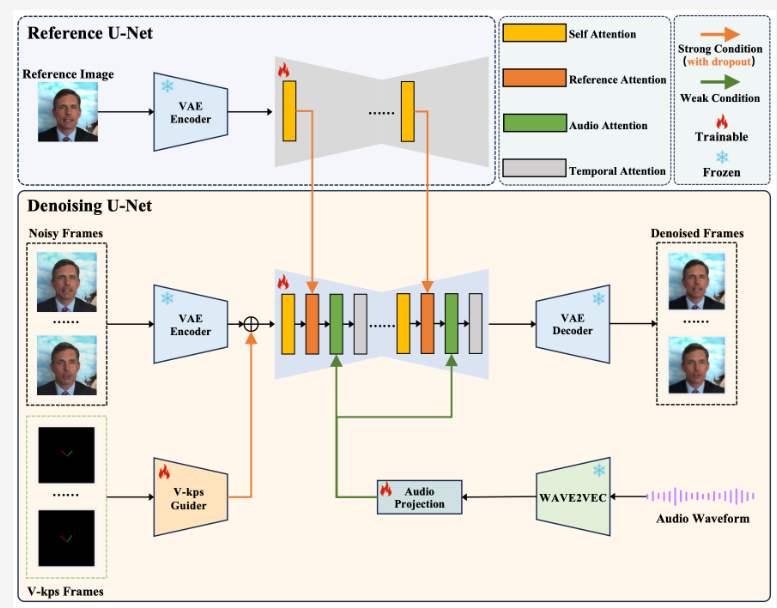
为了验证V-Express模型的性能,腾讯的研发团队进行了一系列实验。实验结果表明,V-Express模型能够有效生成受音频控制的肖像视频。这意味着,用户只需提供一张人像照片和一段音频,就可以生成一个与音频同步的肖像视频。这在以往的研究中是一个难以实现的突破。
此外,V-Express模型还表现出了对其他控制信号的强大适应能力。无论是姿态、输入图像还是其他类型的控制信号,V-Express都能够通过逐步丢弃操作,实现对这些信号的有效利用和平衡。这使得V-Express模型在肖像视频生成领域具有极高的灵活性和可定制性。
AI旋风认为,V-Express模型的开源将极大地推动肖像视频生成领域的发展。随着越来越多的研究者和开发者加入这一领域,我们有望看到更多基于V-Express模型的创新应用涌现。这些应用将不仅限于娱乐和广告领域,还将拓展到虚拟偶像、在线教育、远程医疗等多个领域。
腾讯公司表示,将继续深入研究V-Express模型,并探索其在更广泛领域的应用。同时,腾讯也欢迎全球的研究者和开发者加入V-Express的开源社区,共同推动肖像视频生成技术的进一步发展。
总之,V-Express模型的开源为肖像视频生成领域带来了新的发展机遇。我们有理由相信,在不久的将来,基于V-Express模型的创新应用将改变我们的生活和工作方式,为我们带来更多的便利和乐趣。
相关文章
