在人工智能领域的浪潮中,大模型技术以其卓越的性能和广泛的应用前景备受瞩目。近日,昆仑万维公司宣布开源了其研发的稀疏大型语言模型Skywork-MoE,这一突破性的技术成果不仅彰显了昆仑万维在AI领域的创新能力,更为整个大模型社区带来了深远的影响。
AI旋风认为,Skywork-MoE的开源不仅是技术进步的体现,更是推动人工智能领域发展的重要举措。该模型在保持性能强劲的同时,大幅降低了推理成本,为应对大规模密集型LLM带来的挑战提供了有效的解决方案。
Skywork-MoE模型作为一个专家混合模型(MoE),通过将计算分配给专门的子模型或“专家”,实现了在经济上的更可行替代方案。这一设计不仅提高了模型的计算效率,还降低了对硬件资源的需求。更值得一提的是,Skywork-MoE是首个支持用单台4090服务器推理的开源千亿MoE大模型,这一特性使得其在实际应用中更具灵活性和可扩展性。
在技术细节方面,Skywork-MoE的模型权重可在Hugging Face上下载,开源仓库位于GitHub,方便广大开发者进行研究和应用。此外,昆仑万维团队还提供了支持8×4090服务器上8bit量化加载推理的代码,进一步降低了推理成本。在8×4090服务器上,使用昆仑万维团队首创的非均匀Tensor Parallel并行推理方式,Skywork-MoE可以达到2200tokens/s的吞吐量,展现出卓越的性能。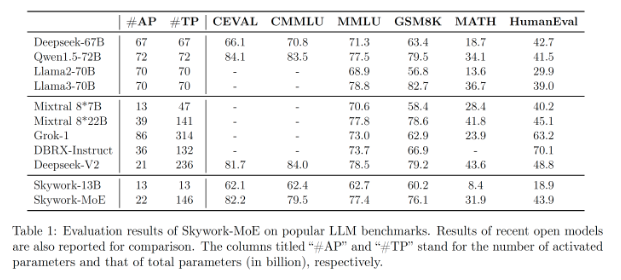
从模型性能和技术创新的角度来看,Skywork-MoE的总参数量为146B,激活参数量22B,共有16个Expert,每个Expert大小为13B。在相同的激活参数量下,Skywork-MoE的能力在行业前列,接近70B的Dense模型,而推理成本有近3倍的下降。这一成绩的背后,是昆仑万维团队在训练优化算法和大规模分布式训练技术上的持续创新。
为了解决MoE模型训练困难和泛化性能差的问题,Skywork-MoE设计了两种训练优化算法:Gating Logits归一化操作和自适应的Aux Loss。这些算法不仅提高了模型的训练效率,还增强了模型的泛化能力。在分布式训练方面,Skywork-MoE采用了Expert Data Parallel和非均匀切分流水并行等先进技术,使得计算/显存负载更均衡,进一步提高了训练效率。
除了技术上的创新外,昆仑万维还通过一系列实验和经验规则来验证Skywork-MoE的性能和效果。其中,Scaling Law实验探究了影响Upcycling和From Scratch训练MoE模型好坏的约束;而训练经验规则则提供了在实际应用中选择训练方式的指导原则。
Skywork-MoE的开源为大模型社区带来了一个强大的新工具,有助于推动人工智能领域的发展。特别是在需要处理大规模数据和计算资源受限的场景中,Skywork-MoE凭借其高效、灵活和可扩展的特性,将发挥重要作用。同时,昆仑万维的这一举措也体现了其在AI领域的开放和合作精神,为整个社区的发展注入了新的活力。
相关文章
