在人工智能的浪潮中,深度学习技术不断突破,推动着各个领域的进步。近日,字节跳动凭借其卓越的技术实力,发布了新一代的Depth Anything V2深度模型,这一里程碑式的创新成果,无疑为单眼深度估计领域带来了前所未有的性能提升。
Depth Anything V2深度模型在单眼深度估计领域实现了显著的性能飞跃。相较于前代Depth Anything V1,V2版本不仅在细节上进行了优化,提供了更精细的深度预测,而且在效率和准确性上也取得了显著提升。据官方数据显示,V2模型在速度上比基于Stable Diffusion的模型快了10倍以上,这无疑将极大提高实际应用中的效率。
该模型的核心优势在于其多规模模型支持。为了满足不同应用场景的需求,字节跳动提供了参数从25M到1.3B不等的多种规模模型。这种灵活性使得Depth Anything V2能够广泛应用于各种场景,无论是需要高精度深度估计的自动驾驶,还是追求高效率的智能家居,都能找到适合的模型。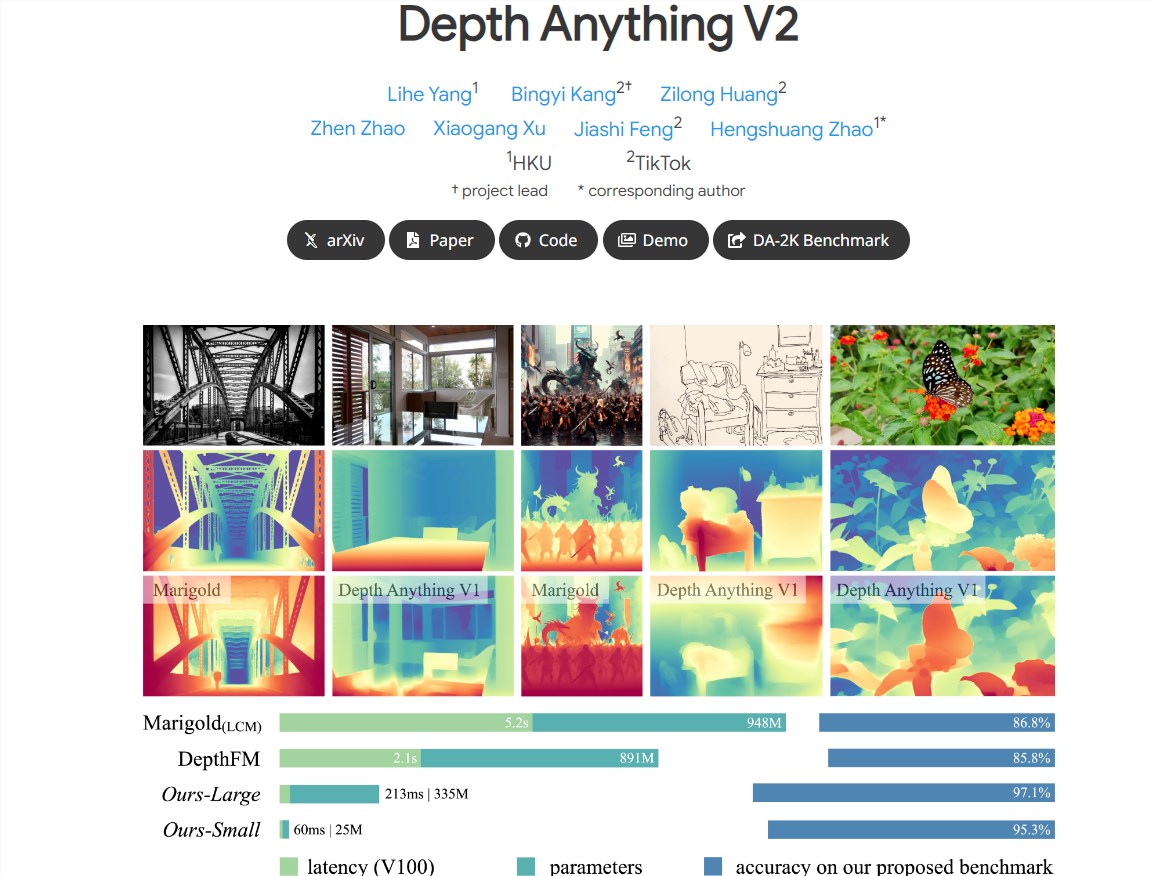
那么,字节跳动是如何实现这一性能飞跃的呢?关键在于三个关键实践。首先,研究人员采用了合成图像替换真实图像的方法,提高了模型的训练效率。通过大量合成图像的训练,模型能够学习到更多的场景和细节,从而提升其在真实世界中的性能。其次,通过扩大教师模型的容量,增强了模型的泛化能力。这使得模型能够更好地适应各种复杂场景,提高预测的准确性。最后,利用大规模伪标注图像教授学生模型,提高了模型的鲁棒性。这种方法能够充分利用未标注的真实图像数据,进一步提高模型的性能。
在实际应用中,Depth Anything V2的深度预测能力将带来广泛的应用场景支持。研究人员利用模型的泛化能力,通过度量深度标签进行微调,使得模型能够更好地适应不同领域的需求。此外,为了促进未来研究,研究人员还构建了一个多样化的评估基准,包含稀疏深度注释等多种评估方式。这将为研究人员提供一个全面的评估平台,推动单眼深度估计技术的不断发展。
在训练过程中,研究人员采用了基于合成与真实图像的训练方法。他们首先在合成图像上训练了最大的教师模型,然后为大规模未标注的真实图像生成了高质量的伪标签。利用这些伪标签,研究人员在真实图像上训练了学生模型,从而实现了从合成到真实的无缝过渡。这种训练方法不仅提高了模型的性能,还使得模型能够更好地适应真实世界中的复杂场景。
Depth Anything V2的发布,无疑展示了字节跳动在深度学习技术领域的创新实力。这一模型的高效和准确性能特点预示着其在计算机视觉领域的广泛应用潜力。未来,我们期待看到更多基于Depth Anything V2的创新应用出现,为人类的生活带来更多便利和可能。
相关文章
