近日,Meta携手Ecole des Ponts ParisTech和Université Paris-Saclay的研究团队在人工智能领域取得了突破性进展,发布了一种全新的多token预测技术,该技术能够显著提升大型语言模型(LLMs)的准确性和速度,使AI模型在推理时间上提升了惊人的3倍。
多token预测技术打破了传统自回归语言模型的经典结构,后者一次仅预测一个token。而新研究则通过同时预测多个token,实现了更高的样本效率和更快的推理速度。虽然这一技术并非适用于所有类型的模型和语言任务,但在某些领域中已经展现出了巨大的优势。
据研究人员介绍,传统的LLMs训练方法是“下一个token预测”,这是一种自监督学习技术,模型通过预测文本序列中的下一个token来学习语言规律。然而,这种方法在获取语言、世界知识和推理能力方面存在局限性。新研究的假设是,“训练语言模型同时预测多个未来token会导致更高的样本效率”。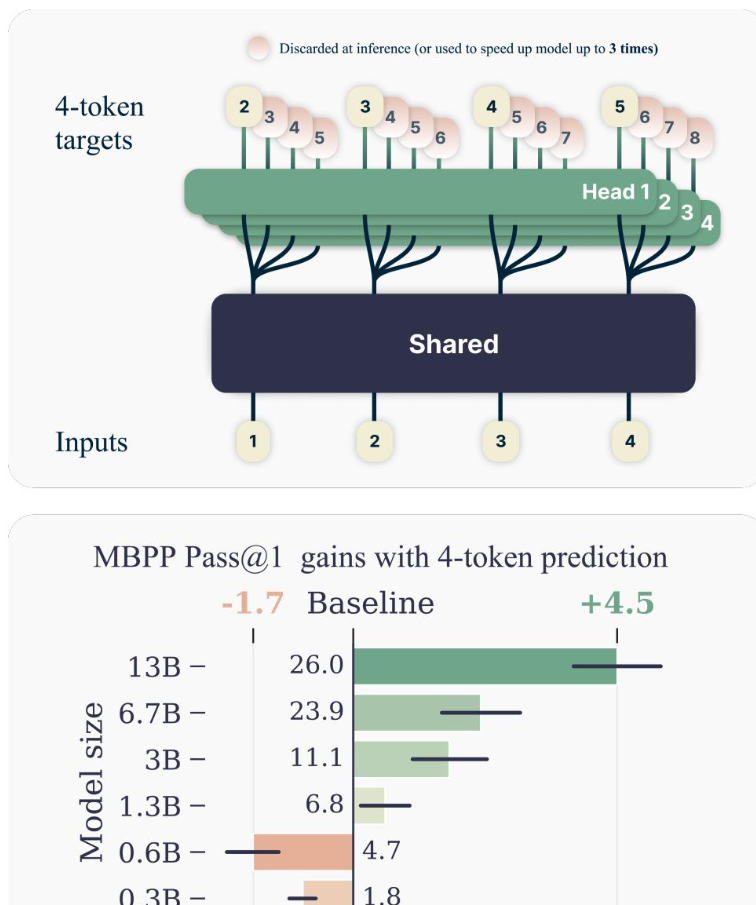
多token预测技术要求LLM同时预测训练语料库中每个位置的多个token。为了实现这一目标,研究人员设计了一种简单而高效的多token预测架构,无需额外的训练时间或内存开销。该架构使得模型能够在一次推理中预测多个token,从而大幅提升了推理速度。
在多种任务上的测试结果表明,多token预测技术在小型模型上可能表现一般,但随着模型规模的增加,其优势逐渐凸显。特别是在“字节级标记化”训练上,多字节预测模型大幅优于基线的单字节预测模型。此外,多token预测技术还使模型在推理时间上提升了3倍,为生成任务提供了更快的推理速度和更高的准确性。
尽管多token预测技术已经取得了显著的成果,但研究人员并未满足于此。他们正在考虑进一步的技术改进,包括自动选择最佳预测token数量的技术,以及研究词汇量和多token预测之间的动态关系。这些改进有望使多token预测技术在未来更加完善,为企业应用提供更强大的支持。
AI旋风认为,Meta发布的多token预测技术对于AI领域的发展具有重要意义。它不仅提升了大型语言模型的准确性和速度,还为生成任务提供了更高效的解决方案。随着技术的不断进步和应用场景的不断拓展,多token预测技术有望在更多领域发挥重要作用,推动人工智能技术的快速发展。同时,这也展示了Meta在人工智能领域的持续创新和领先地位。
 渝公网安备50019002504809号
渝公网安备50019002504809号