近日,谷歌在人工智能领域再次迈出重要步伐,发布了名为PaliGemma的开源视觉语言模型。这款模型凭借其强大的图像处理和语言理解能力,旨在支持包括图像和短视频字幕生成、视觉问答、图像文本理解、物体检测、文件图表解读以及图像分割在内的多种视觉语言任务。PaliGemma的发布不仅彰显了谷歌在AI领域的持续创新力,也为广大研究人员和开发者提供了强大的工具,以推动视觉语言理解技术的发展和应用。
AI旋风认为,PaliGemma的最大亮点在于其多任务支持能力。该模型能够处理多种视觉语言相关的任务,提供了广泛的应用场景。无论是为图像添加字幕,还是通过视觉问答系统回答用户的问题,或是实现图像文本的理解、物体检测和图像分割,PaliGemma都能展现出卓越的性能。这种全面的能力使得PaliGemma在AI领域具有极高的实用价值。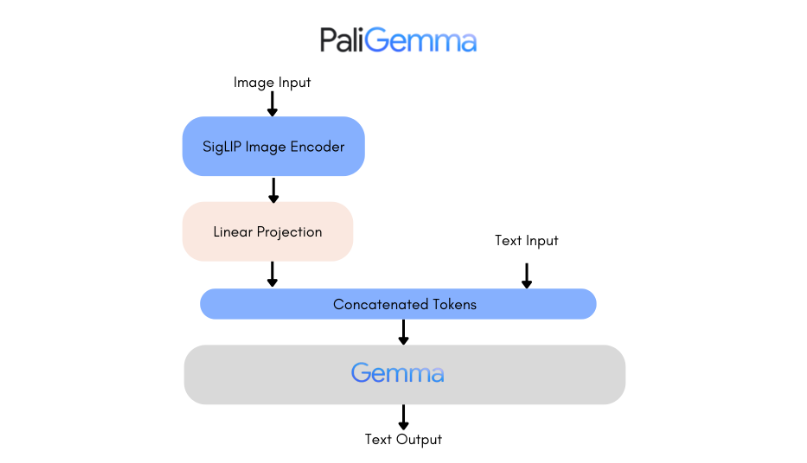
在参数规模方面,PaliGemma包含了30亿(3B)个参数,是一个大型的多模态模型。这样的参数规模保证了模型在处理复杂任务时具有足够的计算能力。同时,PaliGemma的模型架构也值得一提。它结合了SigLiP视觉编码器和Gemma语言模型,分别负责处理图像和文本输入。这种设计使得PaliGemma能够同时处理视觉和语言信息,将两者有效地结合起来。
SigLiP视觉编码器是PaliGemma中的关键组件之一。它负责处理图像输入,将视觉信息编码为模型能够理解的格式。通过先进的视觉编码技术,SigLiP能够捕捉图像中的关键信息,并将其转化为模型可以处理的特征向量。这为PaliGemma在图像处理和视觉语言任务中的表现提供了有力支持。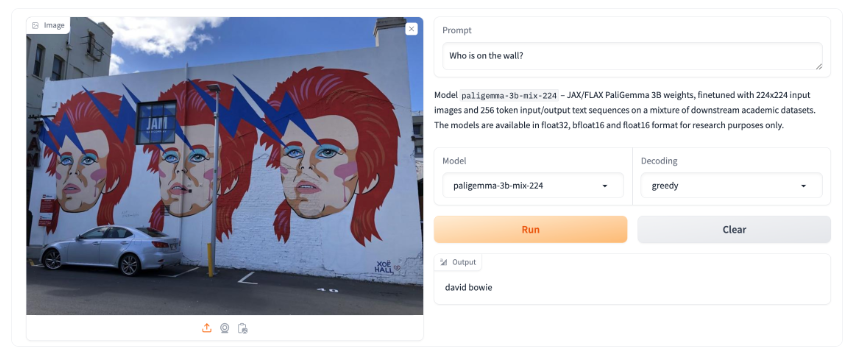
而Gemma语言模型则负责处理文本输入,并生成输出。它能够将图像内容与语言任务结合起来,实现图像和文本之间的有效交互。无论是生成图像字幕,还是进行视觉问答,Gemma语言模型都能根据图像内容生成准确的文本输出。这种能力使得PaliGemma在图像文本理解、物体检测和图像分割等任务中表现出色。
AI旋风认为,PaliGemma的开源特性是其另一个重要优势。通过开源,谷歌将PaliGemma模型分享给了全球的研究人员和开发者。这意味着任何人都可以使用、改进和集成PaliGemma到各种产品和服务中。这种开放合作的模式将极大地推动视觉语言理解技术的发展和应用。
总的来说,谷歌发布的PaliGemma开源视觉语言模型在AI领域具有重要意义。它不仅具有强大的多任务支持能力和参数规模,还结合了先进的视觉编码器和语言模型技术。通过开源合作的方式,PaliGemma将为研究人员和开发者提供强大的工具,推动视觉语言理解技术的发展和应用。我们期待看到PaliGemma在未来能够带来更多的创新和突破。
相关文章
