微软近日在人工智能领域再次迈出重要步伐,发布了全新的大型语言模型系列——Phi-3。这一系列模型包括Phi-3 Vision、Phi-3 Small 7B以及Phi-3 Medium 14B,不仅在性能上与当前行业领先的模型相媲美,更在特定领域展现出独特优势,预示着自然语言处理及相关领域的新一轮创新和应用浪潮。
Phi-3 Medium 14B作为这一系列中的中坚力量,其性能尤为引人注目。根据微软官方公布的数据,Phi-3 Medium 14B的性能与Mixtral 8x22B和Llama 3 70B相当,甚至在某些测试中超越了Command R+ 104B和GPT 3.5。这一卓越表现使得Phi-3系列在大型模型领域具备了强大的竞争力,有望在未来的自然语言处理任务中发挥重要作用。
尽管Phi-3 Small 7B在模型规模上相对较小,但其性能却毫不逊色。微软官方数据显示,Phi-3 Small 7B的性能超过了Mistral 7B和Llama 3 8B,这意味着在资源有限的场景中,该模型依然能够高效处理大量数据,为开发者提供了更加灵活的选择。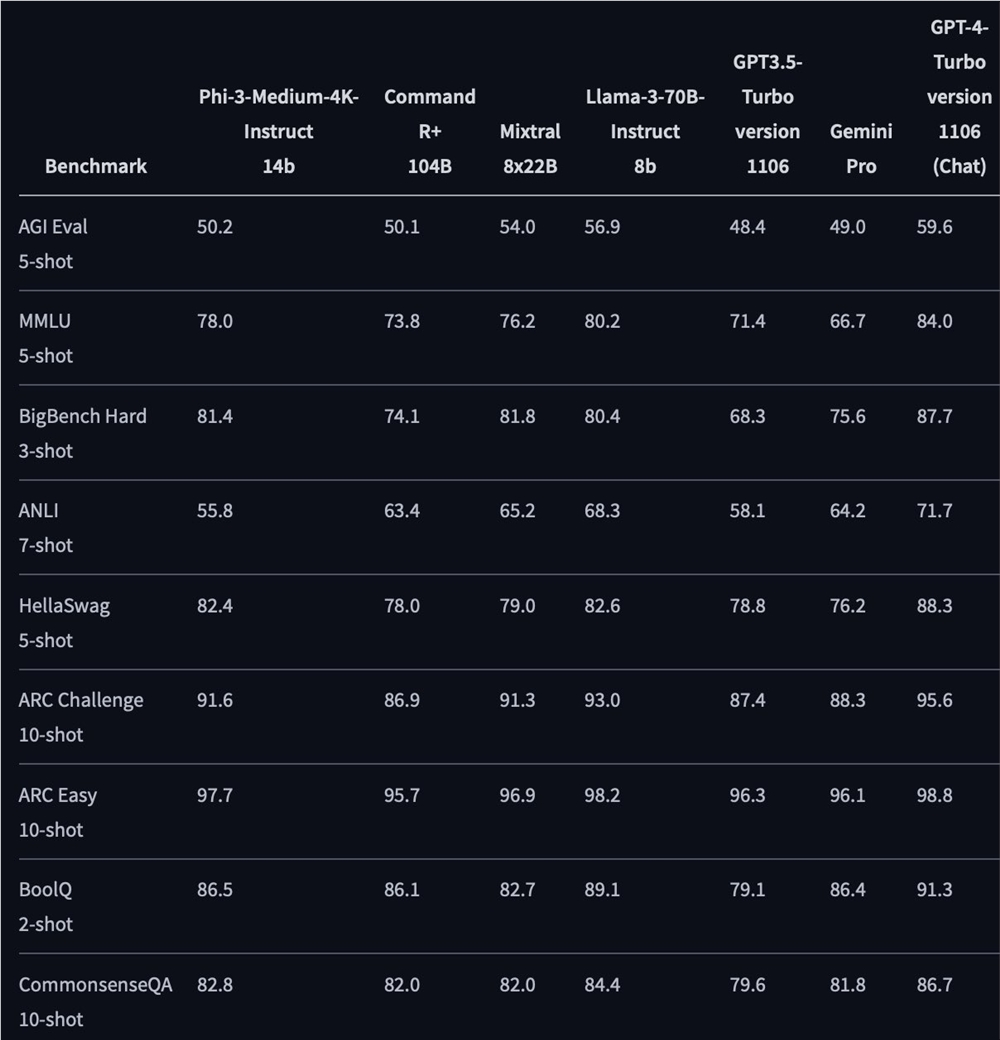
Phi-3系列模型在上下文长度和模型规模方面也表现出色。该系列支持4K和128K的上下文长度,为处理长文本数据提供了极大的灵活性。同时,Medium版本拥有14B参数,Small版本拥有7.5B参数,而Vision版本则具备4.2B参数,满足了不同应用场景的需求。
在训练数据方面,微软投入了大量资源。Phi-3系列模型使用了高达4.8T(万亿)的令牌进行训练,训练过程持续了42天,动用了512个H100 GPU的强大计算能力。训练数据集不仅包含了丰富的多语言数据,还采用了经过严格过滤的数据和合成数据,特别是科学和编程教材。这些举措有助于模型在特定任务上表现更加出色,为科研人员提供了更加精准的数据支持。
值得一提的是,微软还为Phi-3系列引入了一个全新的分词器。这个分词器拥有10万词汇量,能够更准确地理解和生成语言。此外,Phi-3模型的权重兼容AWQ、INT4、ONNX和transformers等主流框架,这为开发者在不同平台上部署和运行模型提供了极大的便利。
AI旋风认为,微软的Phi-3系列模型在大型语言模型领域展现出了强大的性能和灵活性。这一系列的发布,不仅为研究人员和开发者提供了新的工具和可能性,也预示着自然语言处理及相关领域将迎来更多的创新和应用。未来,我们可以期待基于Phi-3系列模型的新技术、新产品不断涌现,为人工智能领域的发展注入新的活力。
相关文章
