AI旋风今日获悉,Meta AI正式推出了一款名为MA-LMM(记忆增强多模态大模型)的新型人工智能模型,旨在解决长期视频理解领域的重大挑战。此举标志着Meta AI在深化多模态处理技术和拓展人工智能应用边界方面迈出了坚实的一步。
长期以来,大型语言模型(LLMs)在文本数据处理方面展现出了惊人的能力,但在处理视频输入时却遭遇了一系列限制。这些限制包括上下文长度限制和GPU内存限制,使得LLMs在处理长视频序列时难以发挥出理想的性能。
为了解决这一问题,Meta AI的研究人员经过深入研究和探索,提出了MA-LMM模型。这款模型采用了记忆增强的方式,通过在线处理视频帧和存储特征,有效地突破了LLMs在处理视频数据时的局限。
据了解,MA-LMM模型的核心思想在于通过顺序处理视频帧,并将关键特征信息存储在长期记忆库中,从而实现对长视频序列中判别信息的有效保留。这一创新性的设计使得MA-LMM能够在不增加GPU内存负担的情况下,显著提高处理长视频序列的效率,有效解决了LLMs面临的上下文长度限制问题。
MA-LMM模型由三个主要组件构成:视觉特征提取器、可训练的查询变压器(Q-Former)以及大型语言模型。视觉特征提取器负责从视频帧中提取关键信息,为后续的处理提供数据支持;可训练的查询变压器则负责根据任务需求对提取的特征进行筛选和整合;而大型语言模型则负责将整合后的特征转化为可理解的文本或语音输出。
这种独特的结构使得MA-LMM模型在处理长视频序列时能够保持高效且准确的性能。实验证明,在各种任务中,MA-LMM均表现出了优越的性能。无论是在长期视频理解、视频问答、视频字幕生成还是在线动作预测等任务中,MA-LMM都取得了显著优于现有模型的效果。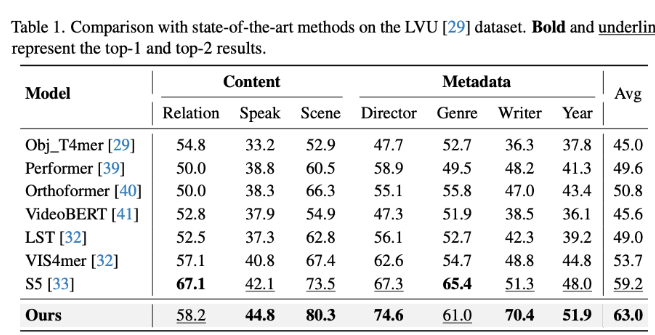
AI旋风认为,MA-LMM的推出不仅是对LLMs在处理视频数据方面的一次重大突破,更是对多模态人工智能技术发展的有力推动。它的成功应用将为视频理解、内容生成和人机交互等领域带来革命性的变革,进一步拓展人工智能技术在各个领域的应用范围。
展望未来,随着MA-LMM模型的进一步优化和完善,我们有理由相信,它将在长视频理解领域发挥更加重要的作用,为人工智能技术的发展注入新的活力。同时,我们也期待着更多类似的创新技术能够在未来涌现出来,共同推动人工智能领域的快速发展。
总的来说,Meta AI推出的MA-LMM模型无疑为多模态人工智能技术树立了新的里程碑。它不仅克服了LLMs在处理视频数据时的限制,更通过其独特的设计和结构实现了对长视频序列的高效处理。我们期待着这一模型在未来的应用和发展中能够带来更多惊喜和突破。
相关文章
