在人工智能与视频生成技术日新月异的今天,一项名为ID-Animator的零样本人类视频生成方法引起了业界的广泛关注。该技术可以在无需进一步训练的情况下,仅凭单个参考面部图像,即可生成高度个性化的视频动画,有效解决了传统视频生成技术在训练效率和身份保持方面的难题。
ID-Animator的出现,无疑为视频生成领域带来了革命性的突破。在传统方法中,生成具有指定身份的高保真人类视频一直是一个技术挑战。要么需要繁琐的逐案微调,导致效率低下;要么在视频生成过程中容易丢失身份细节,影响生成效果。然而,ID-Animator通过引入面部适配器,成功实现了从可学习的面部潜在查询中编码与身份相关的嵌入,从而在无需额外训练的情况下,实现了个性化视频的高效生成。
据了解,ID-Animator继承了现有基于扩散的视频生成框架,并在此基础上进行了创新。为了促进视频生成中身份信息的提取,研究团队还引入了一个面向身份的数据集构建流水线。这一流水线结合了从构建的面部图像池中生成分离的人类属性和动作标题的技术,有效提高了模型对于特定身份视频生成的保真度和泛化能力。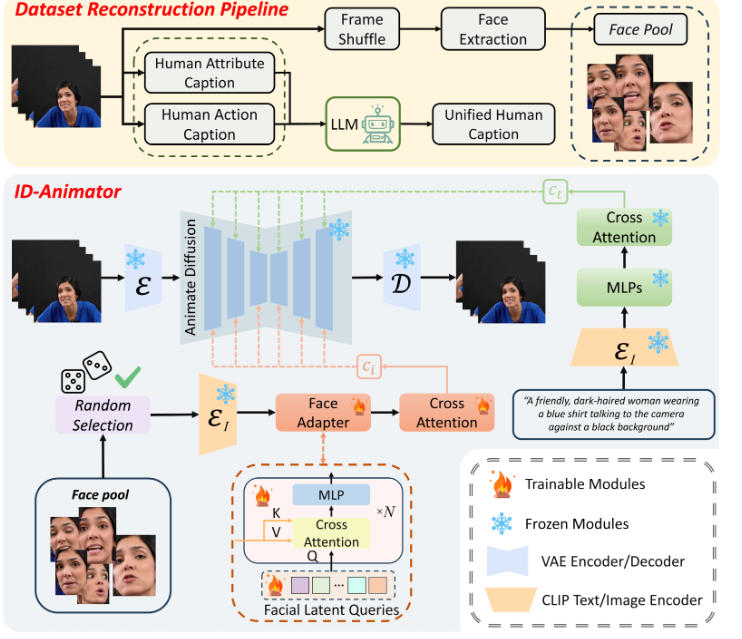
AI旋风认为,ID-Animator的最大亮点在于其随机参考训练机制。在训练过程中,模型会随机从之前提取的面部池中选择一个参考图像。通过这种蒙特卡洛技术,模型能够平均化来自不同参考图像的特征,减少身份不变特征的影响,从而生成更加自然、真实的视频动画。
此外,ID-Animator还展示了强大的生成能力。在基本提示下,模型可以根据文本定制人物的上下文信息,包括头发、服装等特征,创造新颖的角色背景,并使他们执行特定的动作。这种生成能力使得ID-Animator在个性化视频生成领域具有广泛的应用前景。
值得一提的是,ID-Animator还具备身份混合的功能。通过将来自两个不同ID的嵌入以不同比例混合,模型可以在生成的视频中结合两个ID的特征,实现更加丰富的视觉效果。这一功能不仅增加了视频的趣味性,也为创作者提供了更多的创作空间。
另外,ID-Animator与ControlNet的结合也为其增色不少。通过提供单帧或多帧控制图像,用户可以更加精确地控制生成视频的内容和风格。当提供单帧控制图像时,生成的结果能够巧妙地将控制图像与面部参考图像融合;而当提供多个控制图像时,生成的视频序列能够紧密遵循多个图像提供的序列,实现更加灵活的视频生成。
大量实验证明,ID-Animator在生成个性化人类视频方面优于先前的模型。同时,该方法与流行的预训练T2V模型(如animatediff)和各种社区骨干模型高度兼容,显示出其在真实应用中的高度可扩展性。
总的来说,ID-Animator作为一款创新的AI视频生成工具,不仅解决了传统视频生成技术在训练效率和身份保持方面的难题,还通过其强大的生成能力和灵活的控制方式,为个性化视频生成领域带来了全新的可能性。随着技术的不断发展,我们有理由相信,ID-Animator将在未来为视频创作和娱乐产业带来更加深远的影响。
 渝公网安备50019002504809号
渝公网安备50019002504809号