近日,AssemblyAI在语音识别领域取得了重大突破,其最新研究成果——Universal-1模型在多语言环境中的卓越表现引起了业界的广泛关注。这款模型不仅在准确性和鲁棒性方面达到了行业领先水平,更在处理速度上实现了令人瞩目的飞跃,比fast Whisper更快,仅需38秒即可处理60分钟的音频。
Universal-1的出色表现得益于其强大的技术支撑。该模型经过1250万小时的多语言音频数据训练,采用了先进的Conformer RNN-T架构。这种架构赋予了Universal-1在英语、西班牙语和德语等多种语言中的语音转文字能力,且准确性均实现了10%以上的提升。此外,Universal-1还展现出了强大的多语言转录能力,能够轻松应对单个音频文件中包含多种语言的情况。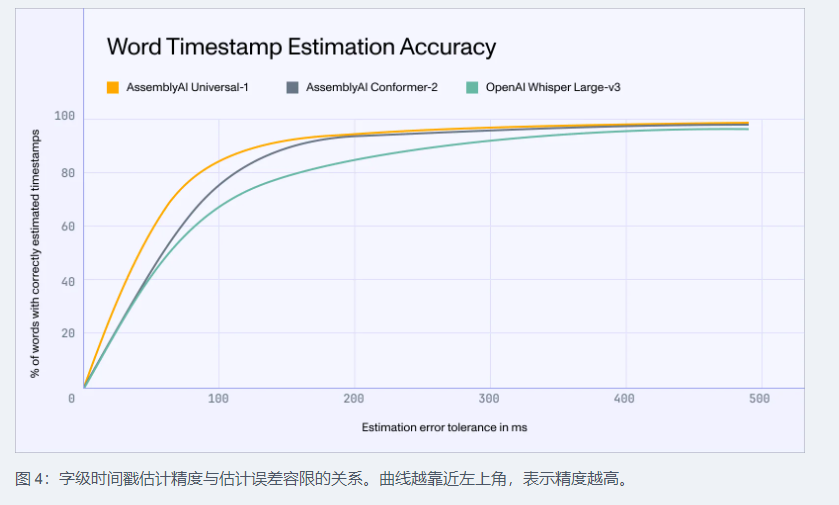
除了语音转文字的准确性,Universal-1在时间戳估计方面也表现出色。对于音视频编辑和说话者辨识等应用场景来说,精确的时间戳至关重要。Universal-1通过优化的解码器实现了13%的时间戳准确度提升,相较于Whisper Large-V3更是提高了26%。这一改进使得Universal-1在处理复杂音频场景时能够更准确地捕捉语音信息,为用户提供更加精准的语音转文字服务。
值得一提的是,Universal-1在处理速度上也实现了显著的提升。相较于传统的语音识别工具,Universal-1的并行推理能力更为高效,能够在相同硬件上实现5倍的加速。这意味着,无论是在处理大量音频文件还是在实时语音识别场景中,Universal-1都能以更快的速度完成任务,为用户提供更加流畅的使用体验。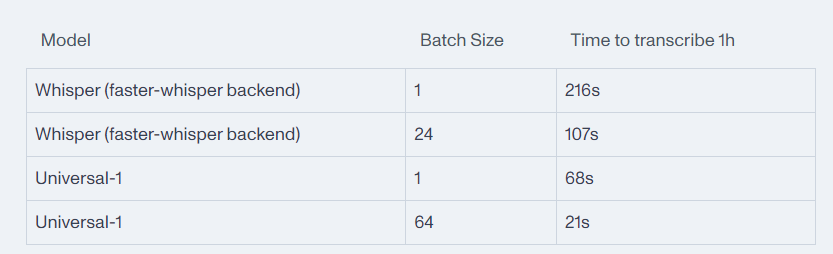
那么,Universal-1是如何实现这些突破的呢?AI旋风了解到,AssemblyAI团队在模型构建方面付出了巨大的努力。他们利用Conformer编码器和RNN-T模型,结合大规模的自监督学习框架和大量的标记数据进行训练。同时,他们还借助Google Cloud TPUs和JAX进行高效的训练,确保模型的稳定性和性能。此外,为了进一步提升模型的准确性和鲁棒性,AssemblyAI团队还采用了各种数据增强方法,使得Universal-1能够应对各种复杂的音频环境。
AssemblyAI的研究成果不仅展示了他们在语音AI领域的领先地位,也为整个行业带来了新的可能性。Universal-1模型的多语言转录能力和高效处理速度将极大地推动语音转文字技术在各个领域的应用。无论是音视频编辑、智能客服还是智能家居等领域,Universal-1都能为用户提供准确、忠实和鲁棒的语音转文字能力,助力企业提升服务质量和效率。
不过,值得注意的是,Universal-1目前并未开源,仅提供API调用。这意味着用户需要通过AssemblyAI提供的接口来使用这款模型。尽管如此但这并不会影响Universal-1在市场上的广泛应用和认可。随着语音AI技术的不断发展,相信未来会有更多优秀的模型涌现出来,为用户带来更加便捷和智能的语音交互体验。
相关文章
