近日,谷歌AI研究团队提出了一种全新的噪声感知训练方法(NAT),为布局感知语言模型的训练领域带来了革命性的进展。该方法针对视觉丰富文档(VRDs)的信息提取(IE)任务,旨在解决传统方法依赖大量人工标记样本的局限性,为文档处理领域的发展注入了新的活力。
AI旋风了解到,VRDs如发票、水电费单和保险报价等,在业务工作流中扮演着重要角色。然而,由于这些文档通常以不同的布局和格式呈现类似信息,从VRDs中实现IE的通用解决方案面临着重大挑战。传统的信息提取方法大多依赖于监督学习,需要大量人工标记的样本进行训练,这不仅耗时耗力,而且成本高昂。
为了克服这一难题,谷歌AI研究团队提出了一种创新的半监督持续训练方法。该方法的核心在于利用噪声感知训练方法(NAT),通过标记和未标记数据的结合,循序渐进地提高抽取器的性能。NAT方法分为三个阶段,旨在在有限的人工标记样本和训练时间内,训练出稳健且高效的文档抽取器。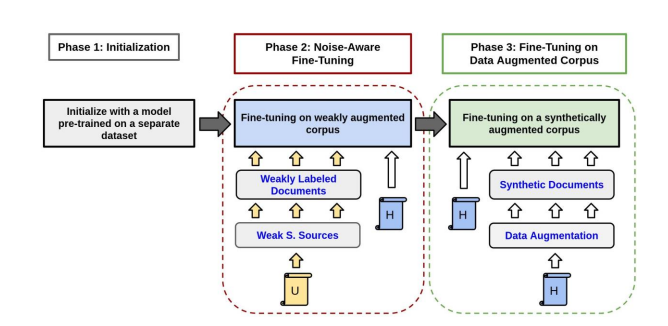
研究团队的核心目标是推动文档处理领域的发展,特别是在企业环境中,实现更高的可扩展性和效率。他们深知,在有限的时间和资源下,如何有效地从VRDs中提取信息是企业面临的重大挑战。因此,他们提出的方法旨在应对这一挑战,通过减少人工工作量和资源消耗,使普通用户能够轻松访问先进的文档处理功能。
NAT方法的提出不仅解决了在严格时间限制内训练强大文档抽取器所固有的挑战,还带来了一系列显著的好处。通过系统地利用标记和未标记数据,该方法有望显著提高企业环境中文档处理工作流的效率和可扩展性。这将有助于企业提高生产力、降低运营成本,并推动整个文档处理领域的进步。
AI旋风认为,谷歌AI研究团队提出的噪声感知训练方法(NAT)为布局感知语言模型的训练领域带来了重要的突破。该方法不仅解决了传统方法依赖大量人工标记样本的问题,而且提高了文档处理的效率和可扩展性。这一创新成果的推出,无疑将为企业在处理海量VRDs时提供更加高效、准确的解决方案,推动文档处理领域迈向新的高度。
此外,NAT方法的提出也为我们展示了半监督学习在文档处理领域的巨大潜力。通过结合标记和未标记数据,我们可以在有限的资源和时间内训练出高性能的模型,为实际应用场景中的文档处理任务提供更加可靠和有效的支持。
展望未来,随着AI技术的不断进步和应用场景的不断拓展,我们有理由相信,谷歌AI研究团队将继续在文档处理领域取得更多创新成果,为企业和普通用户带来更多便利和价值。同时,我们也期待更多研究者和从业者能够加入到这一领域的研究中来,共同推动文档处理技术的发展和应用。
相关文章
