AI旋风报道,在人工智能领域掀起新一波浪潮的智子引擎,近日发布了一款名为Awaker 1.0的全新多模态大模型,这一重大创新不仅标志着中国科研团队在通用人工智能(AGI)领域迈出了坚实步伐,更在写真视频效果上实现了对Sora的超越,展现了其在视觉生成领域的卓越实力。
4月27日,中关村论坛的通用人工智能平行论坛上,智子引擎以一场震撼人心的展示,将这款业界首个真正实现自主更新的多模态大模型推向了前台。Awaker 1.0的出现,不仅刷新了人们对于多模态大模型的理解,更以其创新性的MOE架构和自主更新能力,为通用人工智能的实现提供了强有力的技术支撑。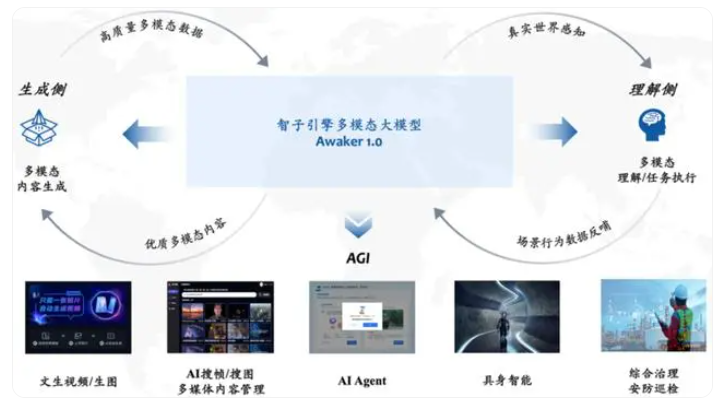
据悉,Awaker 1.0在视觉问答和业务应用任务上的表现尤为出色,其基座模型在性能上超越了GPT-4V、Qwen-VL-Max和Intern-VL等国内外先进模型,展现出了强大的竞争力。而在描述、推理和检测任务上,Awaker 1.0也达到了次好的效果,这充分证明了其多任务MOE架构的有效性和实用性。
更为引人瞩目的是,Awaker 1.0在结合具身智能后,展现出了实现AGI的巨大潜力。具身智能的引入,使得Awaker 1.0能够自主探索环境,发现新策略和解决方案,从而大大提升了其适应性和创造性。这种自我探索、自我反思的能力,正是通用人工智能所追求的核心目标。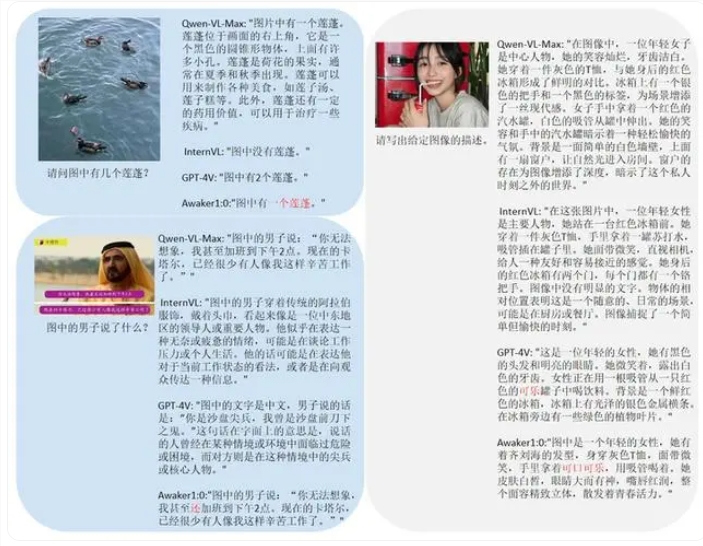
值得一提的是,智子引擎还自主研发了类Sora视频生成底座VDT,作为现实世界的模拟器,VDT不仅展示了Transformer技术在视频生成领域的强大潜力,更在写真视频生成任务上取得了比Sora更好的质量。这一成果无疑将推动视频生成技术的发展,为未来的多模态内容创作提供更多的可能性。
对于Awaker 1.0的发布,智子引擎团队表示,这是他们向实现AGI目标迈进的关键一步。他们相信,AI的自我探索、自我反思等自主学习能力,将是衡量其智能水平的重要标准。而Awaker 1.0在理解侧和生成侧都实现了效果突破,这无疑将加速多模态大模型行业的发展,推动AGI的早日实现。
智子引擎的Awaker 1.0不仅是一款技术领先的多模态大模型,更是一个开启通用人工智能新时代的里程碑。它的出现,将极大地推动人工智能领域的发展,为人类带来更多的便利和惊喜。我们期待在未来,智子引擎能够继续带来更多创新性的成果,引领人工智能走向更加广阔的天地。
相关文章
