AI旋风了解到,Stable Diffusion背后的公司Stability AI近日宣布了新的技术突破。这次,他们带来了图生3D方面的新进展,推出了基于Stable Video Diffusion的Stable Video 3D(SV3D),这一技术能够仅凭一张图片生成高质量的3D网格。
Stable Video Diffusion(SVD)是Stability AI此前推出的高分辨率视频生成模型。而此次SV3D的推出,标志着视频扩散模型首次被应用于3D生成领域,这一创新大大提升了3D生成的质量和视图一致性。
值得注意的是,Stability AI依然延续了其开源的传统,SV3D的模型权重依然对非商业用途开放。想要商业使用,用户需要购买Stability AI的会员。
接下来,AI旋风将深入剖析SV3D的技术细节。SV3D的核心思想是利用视频模型的时间一致性来提升3D生成的一致性。由于视频数据相较于3D数据更易于获取,这使得SV3D的应用更为广泛和便捷。
Stability AI此次提供了两个版本的SV3D:SV3D_u和SV3D_p。前者基于单张图像生成轨道视频,后者则扩展了SV3D_u的功能,可以根据指定的相机路径创建3D模型视频。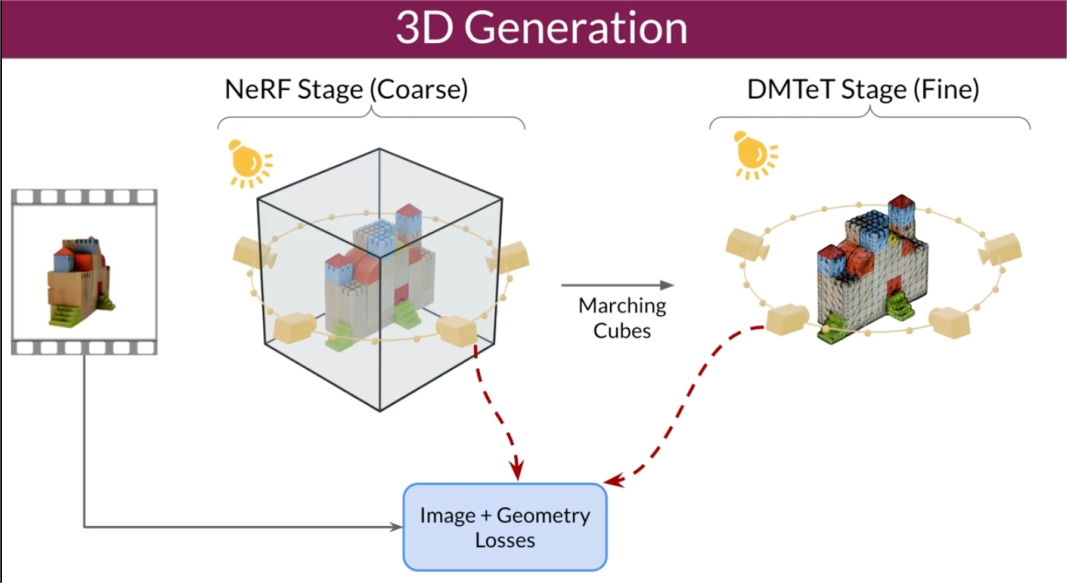
为了优化3D生成过程,研究人员采用了由粗到细的训练策略,并优化了NeRF和DMTet网格。此外,他们还设计了一种名为掩码得分蒸馏采样(SDS)的特殊损失函数,通过优化训练数据中不直接可见的区域,进一步提高了生成3D模型的质量和一致性。
在架构方面,SV3D包含了多层UNet,其中每一层都有一系列残差块(包括3D卷积层)和两个分别处理空间和时间信息的Transformer模块。此外,SV3D还引入了基于球面高斯的照明模型,用于分离光照效果和纹理,从而在保持纹理清晰度的同时减少了内置照明问题。
在实验中,SV3D在Objaverse数据集上进行了训练,并表现出了卓越的性能。在新视角合成(NVS)和3D重建方面,SV3D超越了现有其他方法,达到了业界领先水平。从定性比较的结果来看,SV3D生成的多视角视图细节更丰富,更接近于原始输入图像,这证明了SV3D在理解和重构物体的3D结构方面的强大能力。
AI旋风认为,这一技术的推出无疑将推动3D生成领域的发展,为未来的游戏和视频项目提供更多的可能性。同时,开源的特性也使得更多的开发者能够参与到这一技术的研发和应用中来,共同推动3D生成技术的进步。
据悉,已有一些勇敢的开发者开始尝试在4090上运行SV3D,并取得了不错的效果。未来,我们期待看到更多基于SV3D的创意应用,为我们的生活带来更多的惊喜和乐趣。
相关文章
