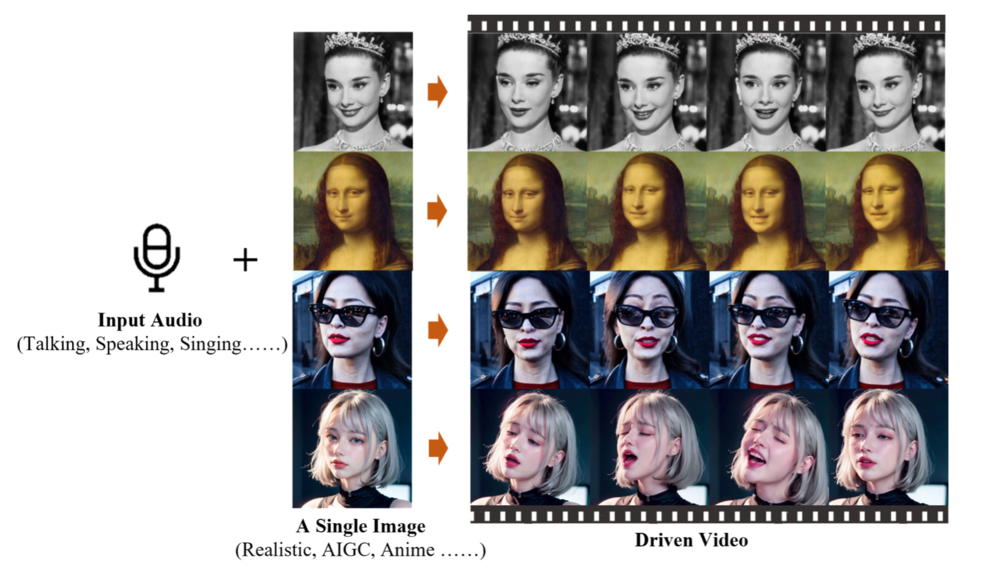
2月28日,阿里巴巴智能计算研究所推出了一款创新的AI模型EMO(Emote Portrait Alive),该模型能够通过一张照片和一段音频,使照片中的人物仿佛在唱歌或说话,而且动作和表情看起来非常自然。
EMO模型的工作原理是,首先通过参考网络从图像和动作中提取特征,然后结合预训练的音频编码器处理声音,利用多帧噪声和面部区域掩码生成视频。该模型还结合了注意力机制和时间模块,以确保视频中角色的一致性和动作的流畅性。
EMO模型的训练基于超过250小时的视频和1.5亿张图像的数据集,这些内容涵盖了演讲、电影、电视剪辑和歌唱表演等多种语言环境,如中文和英文,确保了模型能够捕捉到丰富的人类表达和声音风格。
在技术架构上,EMO采用了类似于Stable Diffusion的UNet结构,并加入了时间模块以生成视频帧。实验结果显示,EMO在生成说话和歌唱视频方面的表现力和真实感均优于现有的技术,如DreamTalk、Wav2Lip和SadTalker。
EMO模型的主要优势包括:
直接音频到视频合成:无需3D模型或面部标志,简化了生成过程,同时保持了高表现力和自然性。
无缝帧过渡与身份保持:确保视频帧之间的过渡自然,角色身份一致,动画生动逼真。
表达力与真实性:能够生成具有高度表现力和真实感的视频,超越现有技术。
灵活的视频时长生成:根据音频长度生成任意时长的视频,提供灵活性。
面向表情的视频生成:专注于通过音频提示生成表情丰富的肖像视频,尤其在说话和唱歌场景中表现出色。
这些特性使EMO在动态肖像视频生成领域具有显著的竞争力,预计将在数字媒体和虚拟内容生成技术领域发挥重要作用,尤其是在追求高度真实感和表现力的场景中。
相关文章
