最近,谷歌在AI领域再次引起热议。谷歌日前发布了一篇新闻稿,其中详细介绍了他们开发的一款名为ASPIRE的专为大语言模型设计的训练框架。
这款框架的核心目标是增强AI模型的选择性预测能力。在自然语言理解和生成内容方面,大语言模型已经展现出令人惊叹的实力,广泛应用于各种创新应用。然而,在高风险决策类场合,由于模型预测的不确定性和“幻觉”问题,其应用仍需谨慎。
为了解决这一问题,谷歌推出了ASPIRE训练框架,为模型引入了“可信度”机制。这意味着模型在输出答案时,会为其提供一个正确的概率评分,从而让使用者对答案的可靠性有更明确的了解。

AI旋风注意到,ASPIRE训练框架在技术层面主要分为三个阶段:“特定任务调整”、“答案采样”和“自我评估学习”。
在“特定任务调整”阶段,谷歌对已接受过基础训练的大型语言模型进行深入训练,专注于强化模型的预测能力。研究人员通过引入一系列可调参数,并在特定任务的训练数据集上微调预训练语言模型,显著提升了模型预测性能,使其能够更好地解决特定问题。
第二阶段是“答案采样”。在这一阶段,经过特定微调后的大型语言模型开始为每个训练问题生成不同的答案。研究人员利用先前学习到的可调参数,为每个问题生成一系列可信度较高的答案。同时,他们采用了“集束搜索(Beam Search)”方法及Rouge-L算法来评估答案的质量。通过这种方式,他们创建了一个用于自我评估学习的数据集,并将生成的答案及评分重新输入给模型,以启动下一阶段的训练。
第三阶段是“自我评估学习”。在这一阶段,研究人员为模型添加了一组专门的可调参数,用于提升模型的自我评估能力。该阶段的目标是让模型学会“自己判断输出的答案准确性”,从而在生成答案时附上答案的正确概率评分。这一创新的设计不仅提高了模型的预测准确性,还增强了其对自身输出的评估能力。
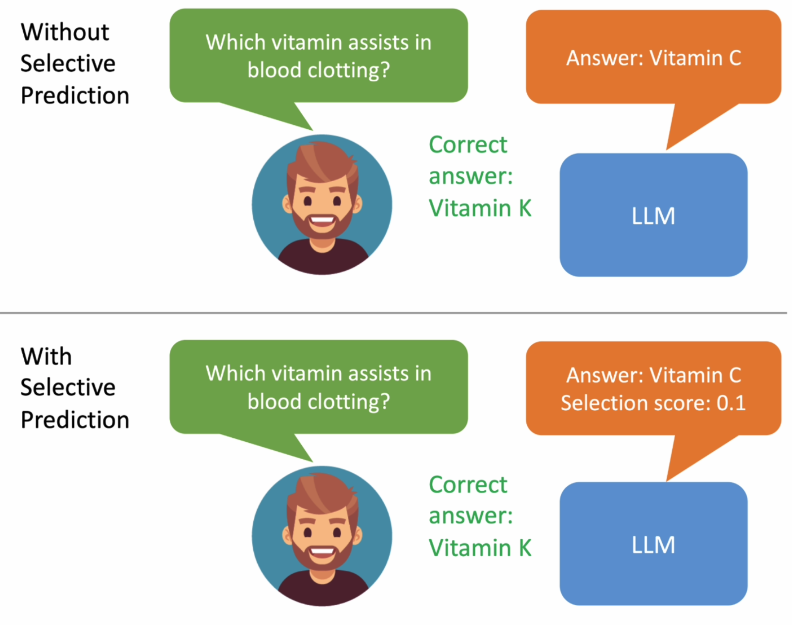
为了验证ASPIRE训练框架的有效性,谷歌研究人员使用了CoQA、TriviaQA和SQuAD三个问答数据集进行实验。实验结果显示,“经过ASPIRE调整的OPT-2.7B小模型表现远超更大的OPT-30B模型”。这一实验结果令人瞩目,表明即使是小语言模型,只要经过适当的调整和训练,也能在某些场景下超越大型语言模型。
研究人员总结称,ASPIRE框架训练能够显著提升大语言模型输出的准确率。即使是较小的模型,在经过微调后也可以进行“准确且有自信”的预测。这一突破性的成果将为大语言模型在实际应用中提供更可靠的预测结果,尤其在高风险决策类场合中。
AI旋风认为谷歌的这一创新无疑将推动大语言模型的发展和应用。通过引入“可信度”机制和多阶段的训练框架,谷歌成功地提高了模型的预测准确性和自我评估能力。
这不仅有助于解决当前大语言模型的“幻觉”问题,还将为未来的AI应用开辟更广阔的可能性。随着技术的不断进步和应用场景的不断拓展,我们期待着更多创新的AI工具和框架的出现,引领自然语言处理领域的持续发展。
相关文章
